Database and data
What is data?
Data
In basic terms, data is facts and figures about anything.
For example, if data were collected on a person, then that data might include their name, age, email, and date of birth.
Database
In our digital world, data is no longer stored in manual files. Instead, developers use something called databases.
Database
A database is a form of electronic storage in which data is organized systematically. It stores and manipulates data electronically to make it more manageable, efficient, and secure.
Examples of Database usage
A bank can use a database to store data for its customers, bank accounts, and transactions.
A hospital uses a database to store patient data, staff data, laboratory data, and much more.
What does database look like?
A database looks like data organized systematically. This organization typically looks like a spreadsheet or a table.
Systematic
All data contains elements or features and attributes by which they can be identified.
For example, a person can be identified by attributes like their age, height, or hair color, and this data is separated and stored in what’s known as entities that represent those elements.
Entity
Entity
An entity is like a table. It contains rows and columns that store data relating to a specific element. In other words, these are relational elements. They’re related to one another.
These entities could be physical representations like an employee, a customer, or a product. Or they could be conceptual like an order, an invoice or a quotation.
Entities then store data in a table-like format against the attributes or features related to the element.
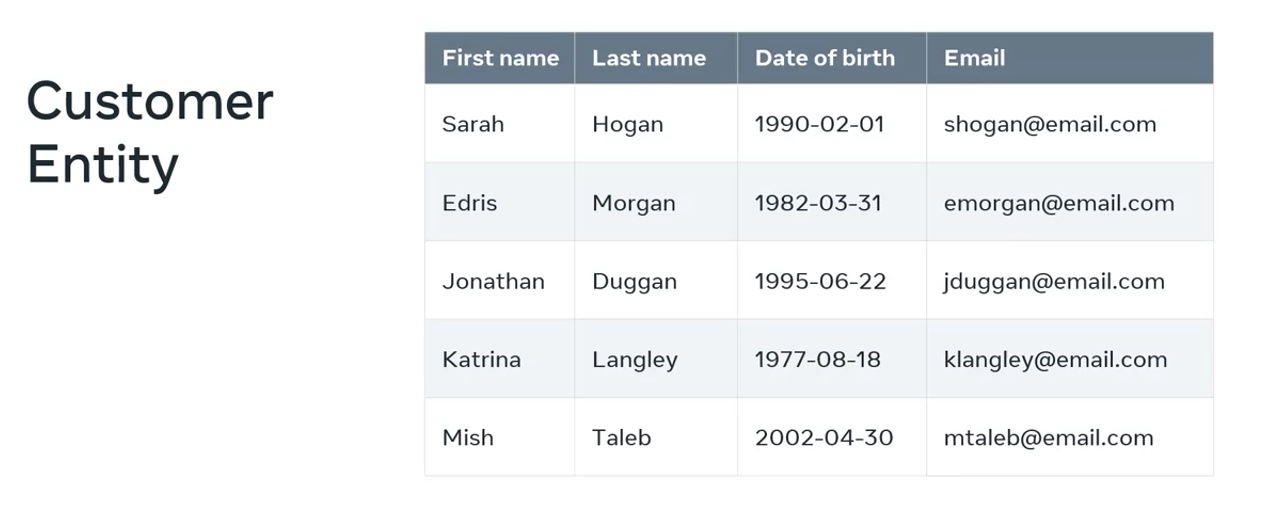
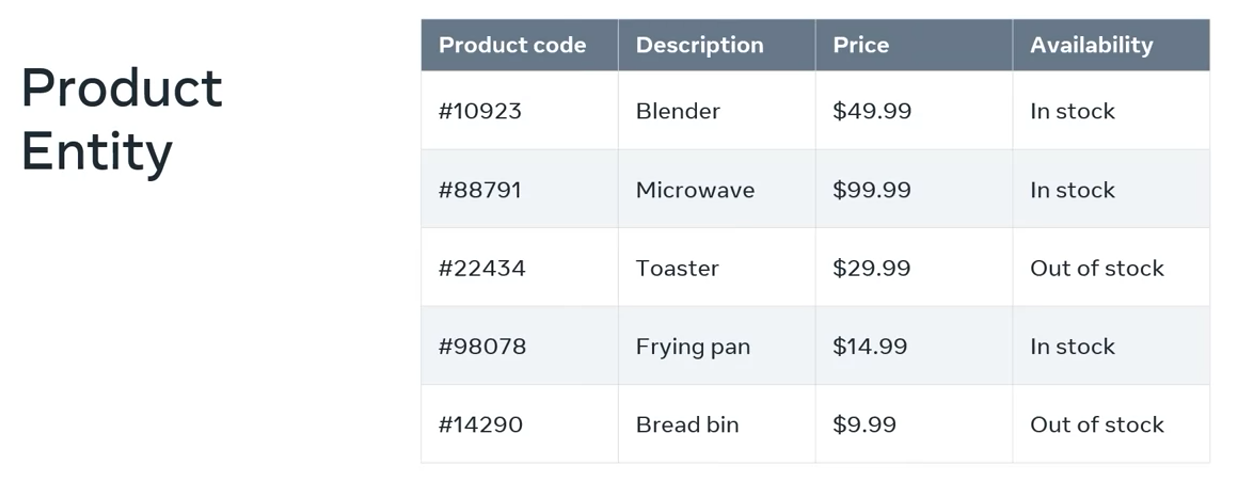
In the relational database world, these entities are known as relations or tables.
The attributes become the columns of the table. Each table row represents an instance of that entity.
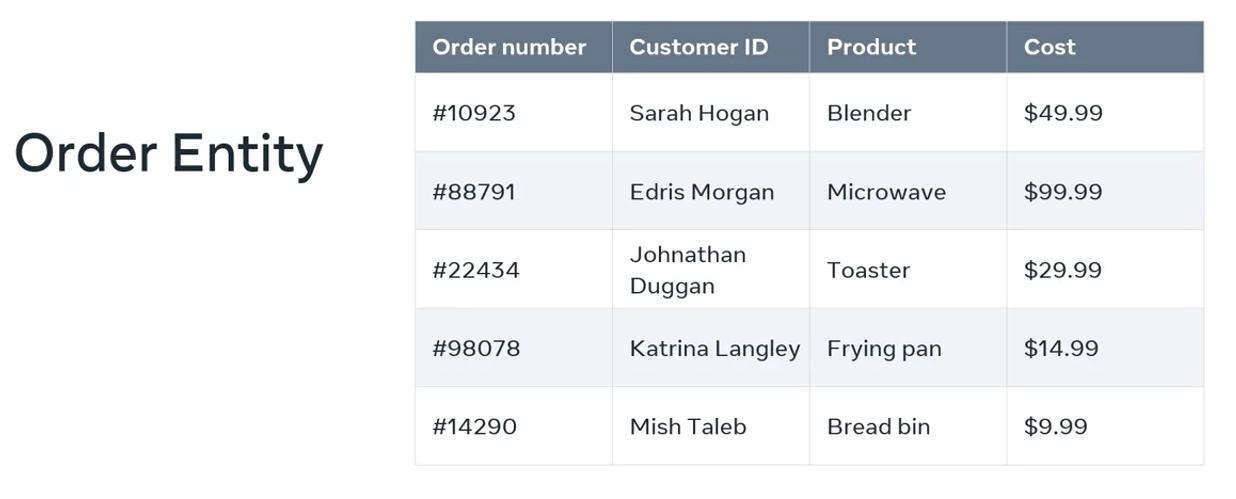
As an example, let’s take the entities from the online store example that you just explored. These two examples could be combined into a list of orders the store received from his customers.
Within a database, this data could be rendered as an order table or entity. The data can be organized into rows that contain:
- a unique order number
- the name of the customer who placed the order
- the product that they ordered
- the price of that product
Types of databases
There are many ways to organize data in a database. Relational databases aren’t the only kind of databases that you’ll encounter. As a Database Engineer, you’ll work with many different types of databases.
Object-oriented database
An object-oriented database is where data is stored in the form of objects instead of tables or relations.
An example of this kind of database could be an online bookstore. The store’s database could render authors, customers, books, and publishers as classes like sets or categories. The objects or instances of these classes would then hold the actual data.
Graph databases
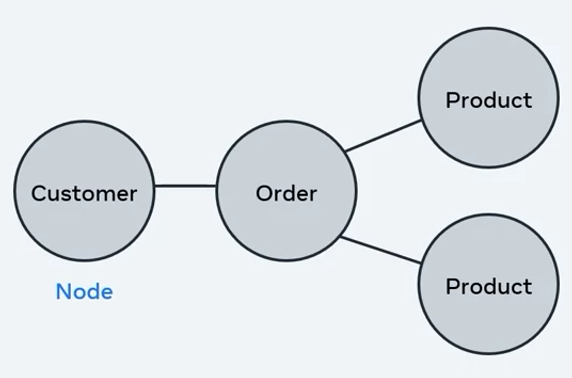
Graph databases store data in the form of nodes.
In this case, entities like customers, orders, and products are represented as nodes. The relationships between them are represented as edges.
Document databases
where data is stored as JSON or JavaScript Object Notation objects.
The data is organized into collections like tables. Within each collection a documents written in JSON that record data.

In this example, customer documents are held in a customer collection while ordering product documents are stored in the ordering product collections.
Where is database itself stored?
A database can be hosted on a dedicated machine within the premises of an organization, or it could be hosted on the Cloud.
Cloud databases are currently a more popular choice. This is because they allow you to store, manage, and retrieve data to a Cloud platform and access data through the Internet, and they all provide a lower-cost option for data management and other similar options.
How is data related?
Data stored in a database cannot exist in isolation. It must have a relationship with other data so that it can be processed into meaningful information.
Let’s explore how data is related by using the online store as our example.
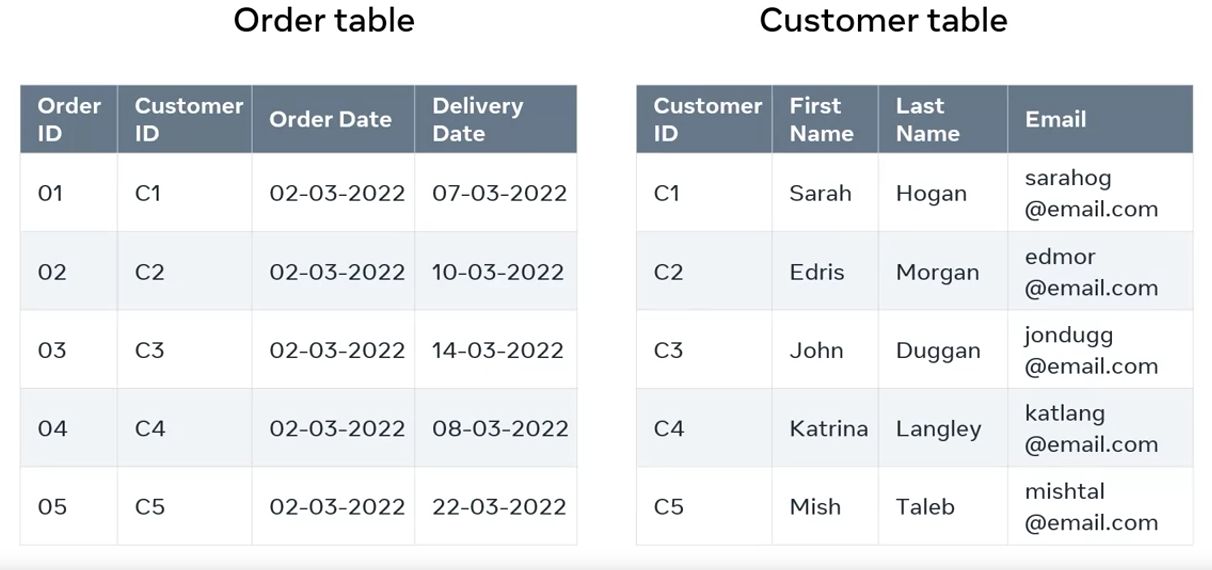
In the database of your online store, you could have an order table and a customer table. To locate the details of a customer’s order, you will check the order number against the customer ID. In other words, the database establishes a link between the data in the tables.
Fields & Records
Let’s look at the customer table in more detail. In this table, the columns are Customer ID, FirstName, LastName, and Email. In relational database terms, these are fields.
Then there are several rows which contain data for each of these fields. In relational databases, they’re known as records of the table.
All these fields and rows work together to store information on the customer, also known as the entity.
Every row and record in the customer table is an instance of the customer entity.
NOTE
What’s most important is that each of these customer instances or records must be uniquely identifiable.
Primary key field
But what if two or more customers share similar info, like the same first name or last name.
To avoid this confusion within the database, you can use a field that contains only unique values like the customer ID.
This is called a primary key field.
It contains unique values that cannot be replicated elsewhere in the table. Even if two customers share the same name, they’ll still have separate customer IDs.
The Customer ID in the order table is there to help identify who it is that place the order.
NOTE
By adding the customer ID field to the order table, our relationship is established between the customer table and the order table, and Because of this relationship, you can pull data in a meaningful way from both tables.
Foreign key field
The customer ID field in the order table is known as the foreign key field.
Foreign key
A foreign key is a field in one table that connects to the primary key field in the original table, which in this case is the customer table.
The customer ID is the primary key of the customer table, but it becomes a foreign key in the order table. This way, the relationship is established and the data in these two tables are related.
Relational data example charts
Data gets collected and stored in databases from various sources for various reasons. For example, customer orders, student course enrollments, and user interaction and feedback to personalize content and improve services.
It’s important to organize data, process it, and present it efficiently to make it more useful and meaningful to people. The way data is related and presented enables people to form a better understanding of existing data. This understanding can be aided by relevant charts that present data visually using combinations of text, symbols, and graphic elements to illustrate the relationship between data in a meaningful way.
Charts can convey a great deal of information and can capture people’s attention in a way that helps them to make better decisions and take suitable actions. Here, you will learn about basic charts commonly used to relate data together and present it in a simple visual way.
Bar chart
A bar chart is a graph that presents categorical data with rectangular bars, where the heights of the bars are proportional to the values that they represent.
For example, the owner of a bookshop in London has had many challenges during the COVID-19 lockdown and wants to know more about their business performance and progress each year from 2019. A bar chart could be very useful to show how sales revenue has changed over the past few years and how the pandemic impacted the business during lockdown.
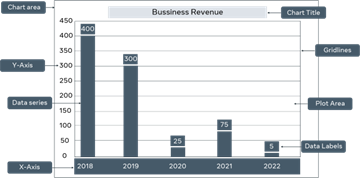
This chart uses bars to present the bookshop’s sales data between 2019 and 2022. The x-axis presents the individual years, while the y-axis presents the sales value. The bars illustrate the sales achieved each year. The taller the bar, the greater the value of sales. In this case, the tallest bar is in 2018, which indicates that this was the most successful year for the business. The smallest bar is in 2022, which indicates that this was the worst year for sales.
Bubble chart
A Bubble chart is another popular type of data chart. It shows how different values compare to each other in terms of bubble size. The smaller bubbles represent smaller values, and the larger bubbles represent larger values.
Let’s examine the bubble chart below, which presents information about the 10 largest countries in the world in terms of population in 2015.
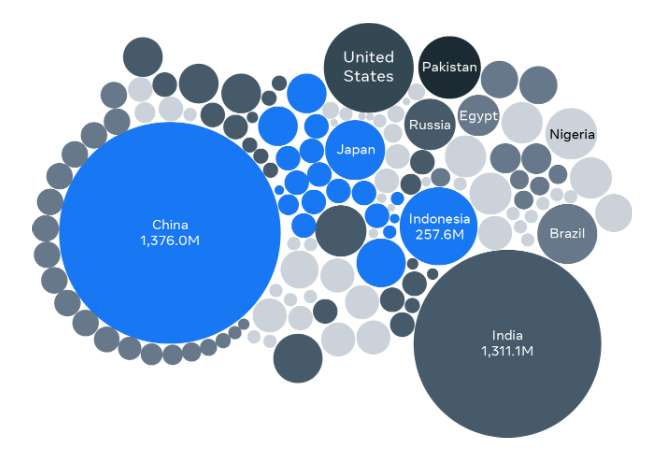
In this example, a country’s population value determines the size of each country’s bubble.
There are large bubbles for China (around 1.4 billion people) and India (about 1.3 billion people), as these countries have the largest populations. Then there are medium-sized bubbles for the USA (about 330 million people) and Indonesia (about 270 million people). Russia (about 145 million people) and Egypt (around 100 million people) have smaller-sized bubbles, as they have smaller comparable populations.
These bubbles give you a good idea of the difference between the countries regarding population sizes. The bubbles also help people to remember this kind of information, as human memory prefers graphical representation of data. After all, “a picture is worth a thousand words”.
Line chart
A line chart presents information as a series of data points called “markers” connected by straight line segments. Line charts are extremely popular and are widely used in most data analytics fields.
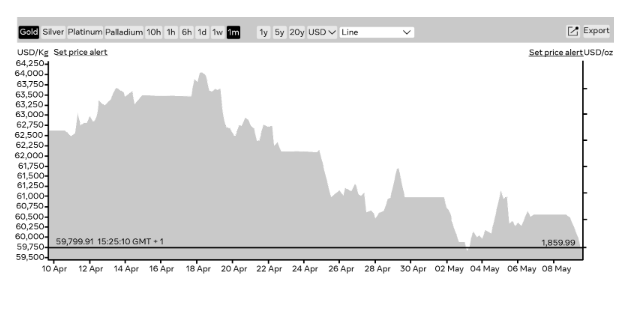
The chart below depicts a company’s gold price over the past month. There is a line that starts with the 10th of April when gold stood at $62,650 for 1kg. This line connects the dots that visualize the change in the gold price over time. The up-and-down movement of the line helps highlight positive and negative changes.
Data analysts commonly use this chart to predict the market’s future based on overall trends.
Pie Chart
A pie chart is another type of data chart that displays how various data make up a whole of 100 percent. In this type of chart, each data point is allocated a “slice” of the pie according to its value.
The following “Sports pie chart” depicts the type of sport students prefer in a class.
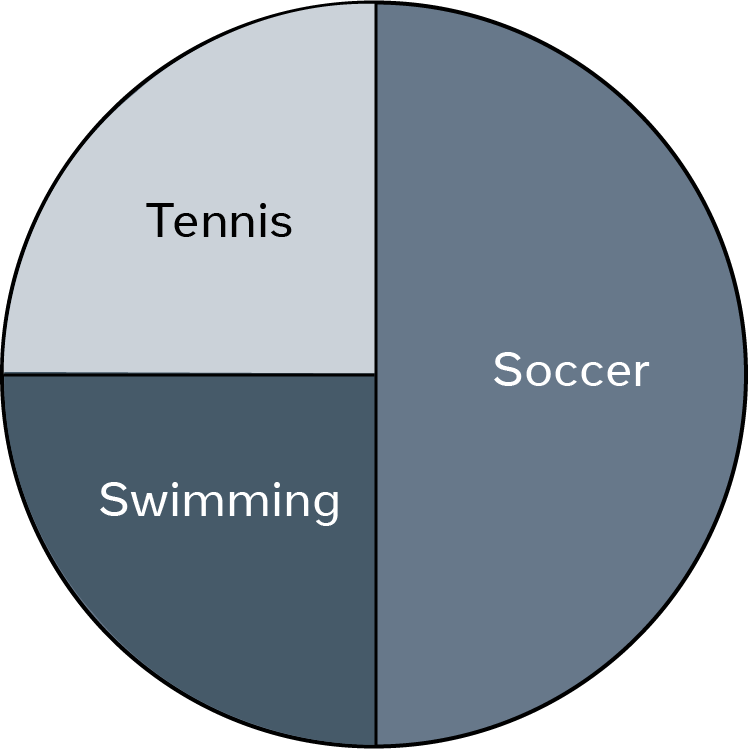
If you ask someone looking at this chart about the percentage of students who like soccer, their answer will be 50%, as it is the slice’s size that helps them to identify the percentage. In this case, “Soccer” occupies half of the pie and, therefore, it is 50% of the whole. “Tennis” and “Swimming” represent the other half of the pie. Since they are equals, each is a quarter of the pie, which is 25% of the whole.
In addition to the charts introduced earlier in this reading, other charts could be used for different purposes. An example is the area chart, which combines the line chart and the bar chart to compare two or more quantities of data. Other commonly used charts include:
- dual axis charts,
- Gantt charts,
- heat maps
- and scatter plot charts.
What chart do I choose to present my data?
Some charts can serve multiple purposes, whereas others are much better at conveying specific types of information to the audience. Line charts, for example, are best used to identify trends that help predict the future. Pie charts are a simple way to show how various parts create a whole. They are also quite easy to build. However, it’s difficult to add a percentage to each slice if there are many slices or if the slices are not exactly a half, a quarter, or a third of the whole.
The answer to the question depends on several factors, including:
- the target audience who will use the information,
- the idea you intend to present,
- and the goal you want to achieve.
Your choice of chart will be determined by the message you want to deliver to your audience, the type and amount of data you want to load to the graph, and so on.
Once you have identified the audience and assessed the data, you can experiment with different charts to find the best option. If multiple charts are suitable to present your data, choose the one that engages your audience and boosts their interest in the information.
By considering all these factors, you should be able to identify the most appropriate chart that serves your purpose.
Alternative types of databases
Relational databases have limitations when it comes to storing data because they mostly store structured data. Yet databases are now required to store more and more unstructured data. So the trend in recent years has been to rely on no sequel databases, instead.
NoSQL databases
NoSQL databases are a type of database that store data in a variety of different formats. Essentially they provide databases with a flexible structure. This makes scaling easy by facilitating a change to the database structure itself without the need for complex data models.
NoSQL databases are used by social media platforms, the Internet of Things, artificial intelligence and other applications that generate massive amounts of unstructured data.
Types of NoSQL databases
- document databases
- Key value databases
- graph databases
Big data & Cloud databases
Essentially these terms are used to describe a recent change in our approach to data and databases.
Big data
Big data
Big data is complex data that can increase in volume with time. In other words is data that can grow exponentially with time.
Where does this kind of complex data come from?
Social media platforms, Online shopping sites and other services generate massive amounts of data every second of the day as they capture the actions of billions of users around the world and with the internet of things or IOT more and more devices are connected to the Internet, generating even more and more data.
All this data is highly unstructured or semi structured. Traditional database systems could deal with structured data using tables, records and relationships. But big data is a whole new challenge.
- Big data is a combination of structured, semi structured and unstructured data collected from many different sources
- and it adds more power to data because it can address complex business problems that traditionally structured data can’t handle.
- Finally, big data helps to provide unique insights that can help to improve decision making. So it’s highly valued across many industries.
For example, the manufacturing sector processes big data to predict equipment failure by evaluating the current state of machinery, assess production processes by monitoring the production line, respond to customer feedback proactively and anticipate future demands by monitoring current sales.
Retail processes big data to anticipate customer demand, improve customer experience, analyze customer behavior and spending patterns and identify pricing improvement opportunities.
The telecommunications sector utilizes big data analytics and network usage analytics to plan for infrastructure investments, design new services that meet customer demands, analyze service quality data to predict customer satisfaction and plan for customer retention mechanisms.
Cloud databases
The use of cloud databases, organizations are moving to the cloud to free themselves from the difficulties of dealing with the infrastructure of physical servers like maintenance and storage costs.
Some examples of cloud storage services include Dropbox and iCloud.
With these cloud storage services, it’s possible to store documents and other data on the cloud, a much more affordable solution.
Business Intelligence
Another trend and databases is business intelligence or B.I. Traditionally databases were just a means of storing data, but organizations now utilize their data with business intelligence related technologies and strategies.
With these technologies, organizations can analyze their data and extract valuable information to help them to make informed business decisions.
Database Evolution
NOTE: This is an optional reading. Don’t worry if you don’t understand all this material. Many of these concepts will be covered at a later stage in the course.
You’ve learned what a database is and how data is related in a database. You’ve also learned about common database projects and alternative types of databases. In this reading, you’ll find out more about the history of database technology and how it evolved.
The history
The history of databases begins in the 1960s with the computerization of databases. Computers emerged as a more cost-effective option for organizations. It also became easier to shift data storage and databases to computers.
The chronological order of the development of databases is as follows:
- (1970s-1990s) - Flat files, hierarchical and network
- (1980s-present) - Relational
- (1990s- present) - Object-oriented, object-relational, web-enabled
Flat files
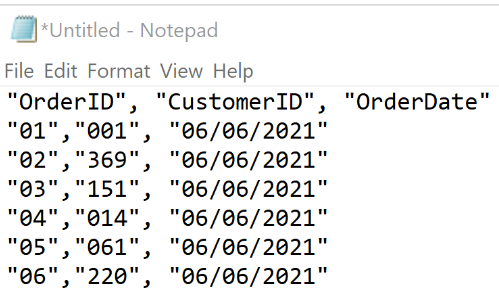
Flat files databases were used during the 1970s-1990s. This is a type of database system that stores data in a single file or table. They are basically text files, where every line contains one record and fields either have fixed lengths or are separated by commas, whitespaces and tabs. Such a file cannot contain multiple tables.
Below is an example of what a flat file database looks like. This text file stores lines of data, where each line represents a record. The fields OrderID, CustomerID and OrderDate are separated by commas.
Hierarchical database systems
Hierarchical database systems that were in use during the same era store data in a hierarchically arranged manner.
Think about it this way: parents can have many children, but one child can only have one parent. In other words, the database represents a one-to-many relationship: all attributes of a specific record are listed under an entity type.
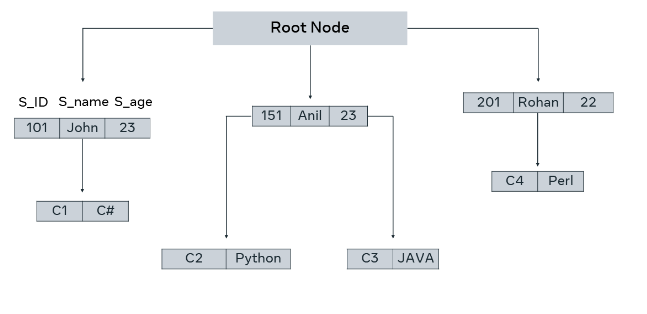
Below is an example of how data is stored in a hierarchical database. In this case, it is data on college students who are taking different courses. A course can be assigned to only a single student, but a student can take as many courses as they want. Thus, there is a one-to-many relationship.
There are three students:
- John,
- Anil
- and Rohan
And there are four courses:
- C#,
- Perl,
- Python
- and Java.
Student and Course are the entity types. John takes C# and Anil takes both Python and Java. Rohan takes Perl.
Network databases
Network databases were introduced by Charles Bachmann. Unlike the hierarchical database model, a network database allows multiple parent and child relationships. In other words, many-to many relationships. In network database terminology, a child record is known as a member. A member or child can be reached through more than one parent, which is called an owner.
A network database has a graph-like structure, and it allows you to represent more complex relationships among data.
Here’s an example of a network database. A teacher can teach multiple courses and a course can have multiple teachers teaching it.
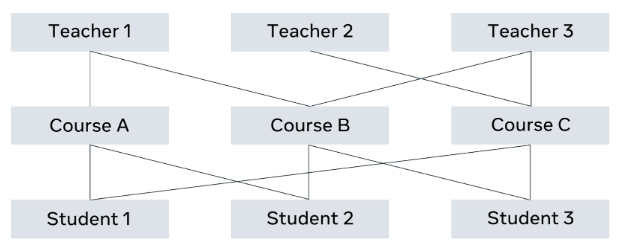
In this era, a language known as the SEQUEL query language was used to work with databases. Later on, with relational databases, this developed into SQL (Structured Query Language) which was made a standard query language to work with databases by the American National Standards Institute once relational database systems were introduced.
Relational database system
The relational database system that was introduced in the 1980s is still the most used database system. It was invented by E. F. Codd and it’s the successor of hierarchical and network database systems. It was viewed as a major paradigm shift in database technology.
In a relational database system, data is stored in tables. The columns of the table hold attributes of the data. Each record usually has a value for each attribute, making it easy to establish the relationships between data points. In a relational database, each row in the table is a record with a unique ID attribute called the primary key. A relational database stores and provides access to data that are related to one another using an attribute known as a foreign key.
Here’s an example of what a Relational Database would look like. Here, there are tables with attributes/ columns that store rows/records of data in them. The relationships between data in tables are established using key columns known as foreign keys that are themselves primary key(s) of a given table. For example, the primary key of the PROFESSOR table is PROF_ID and in the CLASS table, it’s there as a foreign key. It creates the relationship between the PROFESSOR table and the CLASS table. Another example, the COURSE_ID is the primary key of the COURSE table, and it is there in the CLASS table as a foreign key. It establishes the relationship between the COURSE table and the CLASS table.
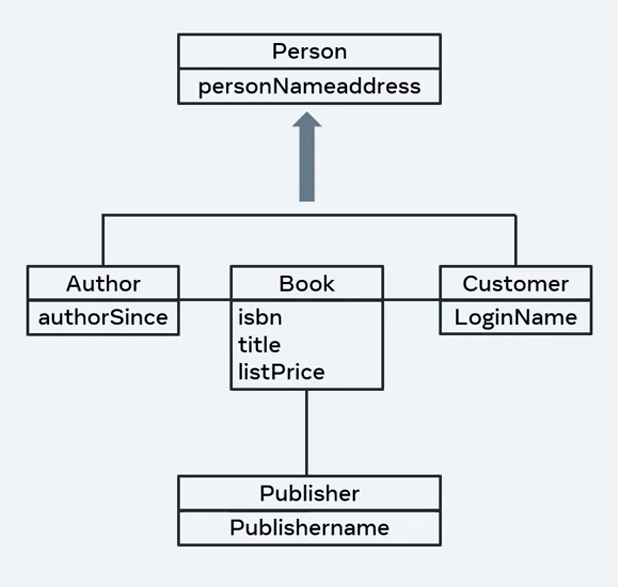
Object-oriented databases
In the 1990s, object-oriented databases were introduced. This was when the object-oriented (OO) programming paradigm became popular and there was a need to represent data in a system as objects as well. Unlike relational databases, object-oriented databases work in the framework of real programming languages like Java and C++, for example.
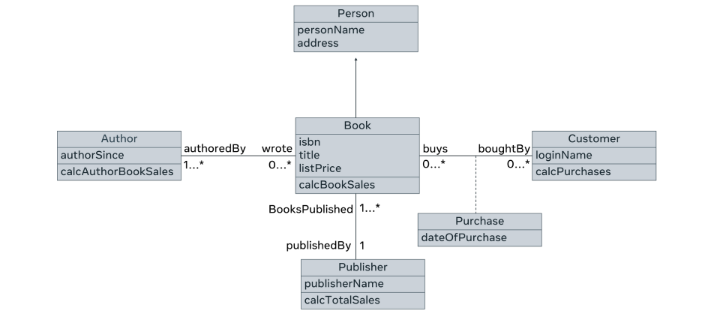
Below is what an object-oriented database looks like. Instead of tables, there are entities or classes like Author, Book and Customer with their attributes and behaviors.
It’s possible to represent data according to OO concepts like inheritance and parent-child relationships among data. For example, an Author and Customer are both descendants of Person. Thus, a person is a generic entity that can represent both an Author and a Customer.
NoSQL databases
Relational databases that are widely used even at present only allows to store structured data. Later on, there was a need to work more and more with unstructured data. This was when NoSQL databases came about as a response to the Internet and the need for faster speed and the processing of unstructured data. NoSQL databases are preferred over relational databases because of their speed and flexibility in storing data. It does not store data in relations or tables that belong to a strict structure. Data can be stored in an ad-hoc manner and they allow to store and process high volumes of different kinds of data. NoSQL databases are capable of processing unstructured big data that’s generated by social media, IoT and others. Therefore, social platforms like Twitter, LinkedIn, Facebook, and Google for example makes use of NoSQL databases.
These are some of the advantages of NoSQL databases:
- Higher scalability
- Distributed
- Lower costs
- A flexible schema
- Can process unstructured and semi-structured data
- Has no complex relationships
Over time there were different types of NoSQL databases that were introduced:
- Document databases store data in documents similar to JSON (JavaScript Object Notation) objects. Each document contains pairs of fields and values. The values can typically be a variety of types including things like strings, numbers, booleans, arrays, or objects.
- Key-value databases are a simpler type of database where each item contains keys and values.
- Wide-column databases store data in tables, rows, and dynamic columns.
- Graph databases store data in nodes and edges. Nodes typically store information about people, places, and things, while edges store information about the relationships between the nodes.
Additional resources
The following resources are some additional reading material that introduces you to the concept of a database, different types of databases, about relational databases in specific and also about the history of databases. These will add to the knowledge that you’ve got on these areas throughout this lesson.
DatabaseBigDataSQLDataCloud-database
Previous one → 3.Git and Github | Next one → 2.Intro to SQL