What is database normalization?
There are several issues that you’re likely to encounter when working with tables such as unnecessary data duplication, issues with updating data and the effort required to query data. Fortunately these issues can be resolved with the use of database normalization.
Normalization
Normalization is an important process used in database systems. It structures tables in a way that minimizes challenges by reducing data duplication, avoiding data modification implications and helping to simplify data queries from the database.
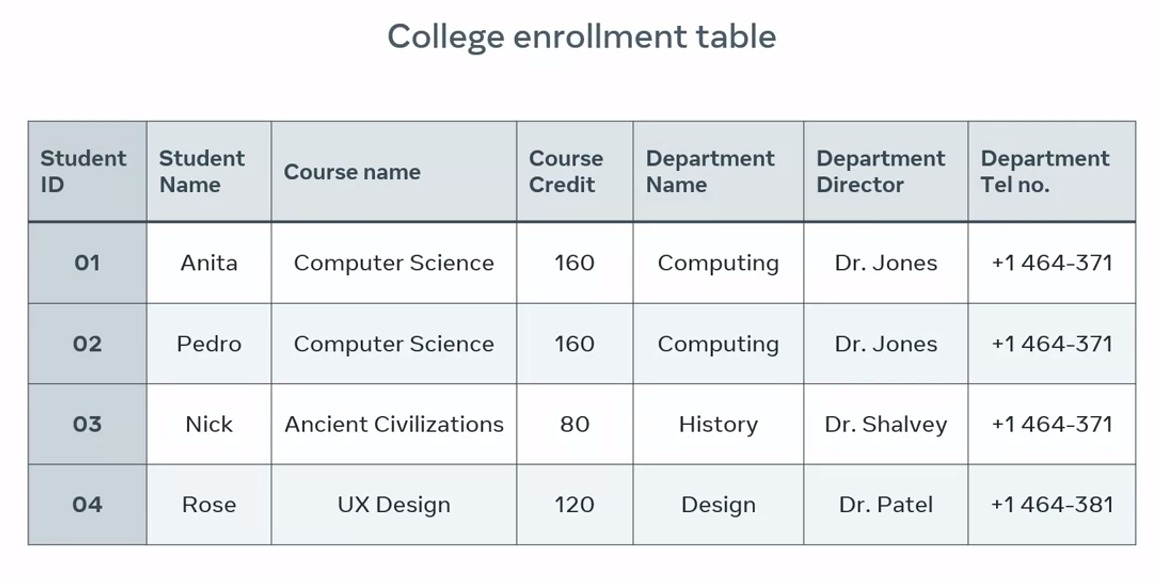
Example of a table that hasn’t been normalized:
The table serves multiple purposes by providing a list of the college students, courses and departments. And the outline of relationships or associations between students, courses and departments. And name and contact details for the head of each department.
WARNING
Creating tables that serve multiple purposes causes serious challenges and problems for database systems. The most common of these challenges include insert anomaly, update anomaly and deletion anomaly.
Insert anomaly
Insert anomaly occurs when new data is inserted into a table which then requires the insertion of additional data. I’ll use the college Enrollment Table to demonstrate an example.
In the college enrollment table, the student ID column serves as the primary key. Each field in a primary key column must contain data before new records can be added to any other column on the table. For example, I can enter a new course name in the table but I can’t add any new records until I enroll new students.
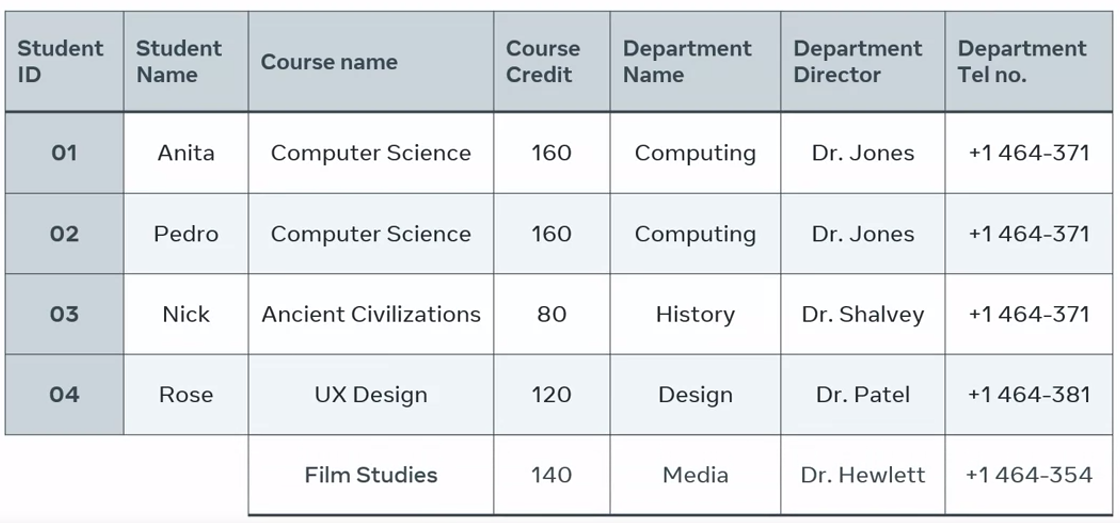
And I can’t enroll new students without assigning each student an ID.
The ID column can’t contain empty fields. So, I can’t insert a new course unless I insert new student data. I’ve encountered the insert anomaly problem.
Update anomaly
An update anomaly occurs when you attempt to update a record in a table column only to discover that this result in further updates across the table.
In the Enrollment Table, the course and department information is repeated or duplicated for each student on that course. This duplication increases database storage and makes it more difficult to maintain data changes.
I’ll demonstrate this with a scenario in which Dr. Jones, the Director of the Computing Department, leaves his post and is replaced with another director. I now need to update all instances of Dr. Jones in the table with the new Director’s name. And I also need to update the records of every student enrolled in the department. This poses a major challenge because if I miss any students, then the table will contain inaccurate or inconsistent information.
Updating data in one column requires updates in multiple others.
Deletion anomaly
A deletion anomaly is when the deletion of a record of data causes the deletion of more than one set of data required in the database.
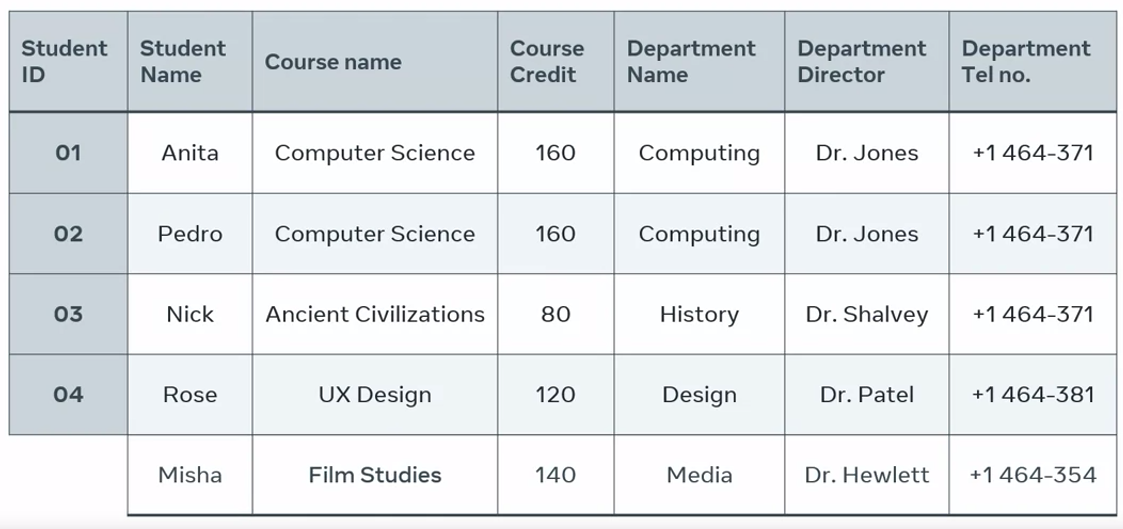
For example, Rose, the student has signed the ID of four has decided to leave her course. So I need to delete her data but deleting Rose’s data results in the loss of the records for the design department as they’re dependent on Rose and her ID.
Removing one instance of a record of data causes the deletion of other records.
So, how can you solve these problems? As you learned earlier, the answer lies in database normalization.
Normalization
Normalization optimizes the database design by creating a single purpose for each table.
To normalize the College Enrollment Table, I need to redesign it. As you discovered earlier, the table’s current design serves three different purposes. So the solution is to split the table in three, essentially, creating a single table for each purpose.
This means that I now have a Student Table with information on each student. A Course Table that contains the records for each course. And a Department Table with information for each department. This separation of information helps to fix the anomaly challenges. It also makes it easier to write sequel queries in order to search for, sort and analyze data.
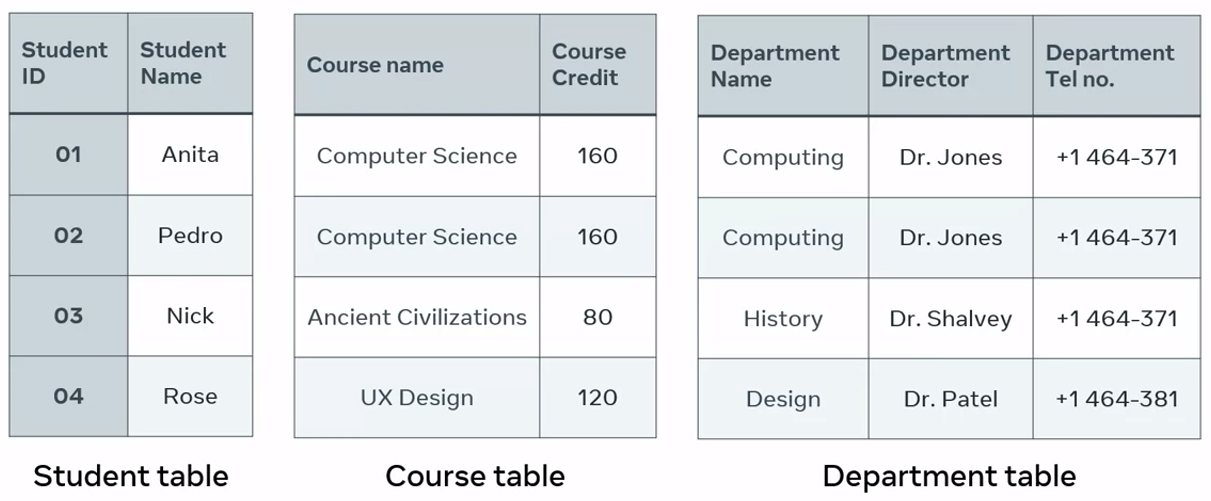
Data normalization
The normalization process aims to minimize data duplications, avoid errors during data modifications, and simplify data queries from the database. The three fundamental normalization forms are known as:
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
In this reading, you will learn how to apply the rules that ensure that a database meets the criteria of these three normal forms.
The following example includes fictitious data required by a Medical Group Surgery based in London to generate relevant reports. Doctors work in multiple regions and various councils in London. And once patients book an appointment, they are given a slot ID at their local surgery. There might be multiple surgeries in the same council but with different postcodes, where one or more councils belong to a particular region. For example, East or West London.
| Doctor ID | Doctor name | Region | Patient ID | Patient name | Surgery Number | Surgery council | Postcode | Slot ID | Total Cost |
|---|---|---|---|---|---|---|---|---|---|
| D1 | Karl | West London | P1 P2 P3 | Rami Kim Nora | 3 | Harrow | HA9SDE | A1 A2 A3 | 1500 1200 1600 |
| D1 | Karl | East London | P4 P5 | Kamel Sami | 4 | Hackney | E1 6AW | A1 A2 | 2500 1000 |
| D2 | Mark | East London | P5 P6 | Sami Norma | 4 | Hackney | E1 6AW | A3 A4 | 1500 2000 |
| D2 | Mark | West London | P7 P1 | Rose Rami | 5 | Harrow | HA862E | A4 A5 | 1000 1500 |
The data listed in the table are in an unnormalized form. Repeating groups of data appear in many cases, for instance, doctors, regions, and council names. There are also multiple instances of data stored in the same cell, such as with the patient name and total cost columns. This makes it difficult to update and query data. Moreover, it is not easy to choose a unique key and assign it as a primary key.
This unnormalized table can be written in SQL form as follows:
CREATE TABLE Surgery
(DoctorID VARCHAR(10),
DoctorName VARCHAR(50),
Region VARCHAR(20),
PatientID VARCHAR(10),
PatientName VARCHAR(50),
SurgeryNumber INT, Council VARCHAR(20),
Postcode VARCHAR(10),
SlotID VARCHAR(5),
TotalCost Decimal);First normal form
To simplify the data structure of the surgery table, let’s apply the first normal form rules to enforce the data atomicity rule and eliminate unnecessary repeating data groups. The data atomicity rule means you can only have one single instance value of the column attribute in any table cell.
The atomicity problem only exists in the columns of data related to the patients. Therefore, it is important to create a new table for patient data to fix this. In other words, you can organize all data related to the patient entity in one separate table, where each column cell contains only one single instance of data, as depicted in the following example:
| Patient ID | Patient name | Slot ID | Total Cost |
|---|---|---|---|
| P1 | Rami | A1 | 1500 |
| P2 | Kim | A2 | 1200 |
| P3 | Nora | A3 | 1600 |
| P4 | Kamel | A1 | 2500 |
| P5 | Sami | A2 | 1000 |
| P6 | Norma | A5 | 2000 |
| P7 | Rose | A6 | 1000 |
This table includes one single instance of data in each cell, which makes it much simpler to read and understand. However, the patient table requires two columns, the patient ID and the Slot ID, to identify each record uniquely. This means that you need a composite primary key in this table. To create this table in SQL you can write the following code:
CREATE TABLE Patient
(PatientID VARCHAR(10) NOT NULL,
PatientName VARCHAR(50),
SlotID VARCHAR(10) NOT NULL,
TotalCost Decimal,
CONSTRAINT PK_Patient
PRIMARY KEY (PatientID, SlotID)); Once you have removed the patient attributes from the main table, you just have the doctor ID, name, region, surgery number, council and postcode columns left in the table.
| Doctor ID | Doctor name | Region | Surgery Number | Surgery council | Postcode |
|---|---|---|---|---|---|
| D1 | Karl | West London | 3 | Harrow | HA9SDE |
| D1 | Karl | East London | 4 | Hackney | E1 6AW |
| D2 | Mark | West London | 4 | Hackney | E1 6AW |
| D2 | Mark | East London | 5 | Harrow | HA862E |
You may have noticed that the table also contains repeating groups of data in each column. You can fix this by separating the table into two tables of data: the doctor table and the surgery table, where each table deals with one specific entity.
Doctor table
| Doctor ID | Doctor name |
|---|---|
| D1 | Karl |
| D2 | Mark |
Surgery table
| Surgery Number | Region | Surgery council | Postcode |
|---|---|---|---|
| 3 | West London | Harrow | HA9SDE |
| 4 | East London | Hackney | E1 6AW |
| 5 | West London | Harrow | HA862E |
In the doctor table, you can identify the doctor ID as a single-column primary key. This table can be created in SQL by writing the following code:
CREATE TABLE Doctor
(DoctorID VARCHAR(10),
DoctorName VARCHAR(50), PRIMARY KEY (DoctorID)
); Similarly, the surgery table can have the surgery number as a single-column primary key. The surgery table can be created in SQL by writing the following code:
CREATE TABLE Surgery
(SurgeryNumber INT NOT NULL,
Region VARCHAR(20), Council VARCHAR(20),
Postcode VARCHAR(10), PRIMARY KEY (SurgeryNumber)
);By applying the atomicity rule and removing the repeating data groups, the database now meets the first normal form.
Second normal form
In the second normal form, you must avoid partial dependency relationships between data. Partial dependency refers to tables with a composite primary key. Namely, a key that consists of a combination of two or more columns, where a non-key attribute value depends only on one part of the composite key.
Since the patient table is the only one that includes a composite primary key, you only need to look at the following table.
| Patient ID | Patient name | Slot ID | Total Cost |
|---|---|---|---|
| P1 | Rami | A1 | 1500 |
| P2 | Kim | A2 | 1200 |
| P3 | Nora | A3 | 1600 |
| P4 | Kamel | A1 | 2500 |
| P5 | Sami | A2 | 1000 |
| P5 | Sami | A3 | 1000 |
| P6 | Sami | A4 | 1500 |
| P7 | Norma | A5 | 2000 |
| P8 | Rose | A6 | 1000 |
| P1 | Rami | A7 | 1500 |
In the patient table, you must check whether any non-key attributes depend on one part of the composite key. For example, the patient’s name is a non-key attribute, and it can be determined by using the patient ID only.
Similarly, you can determine the total cost by using the Slot ID only. This is called partial dependency, which is not allowed in the second normal form. This is because all non-key attributes should be determined by using both parts of the composite key, not only one of them.
This can be fixed by splitting the patient table into two tables: patient table and appointment table. In the patient table you can keep the patient ID and the patient’s name.
| Patient ID | Patient name |
| P1 | Rami |
| P2 | Kim |
| P3 | Nora |
| P4 | Kamel |
| P5 | Sami |
| P7 | Norma |
| P8 | Rose |
The new patient table can be created in SQL using the following code:
CREATE TABLE Patient
(PatientID VARCHAR(10) NOT NULL,
PatientName, VARCHAR(50), PRIMARY KEY (PatientID)
); However, in the appointment table, you need to add a unique key to ensure you have a primary key that can identify each unique record in the table. Therefore, the appointment ID attribute can be added to the table with a unique value in each row.
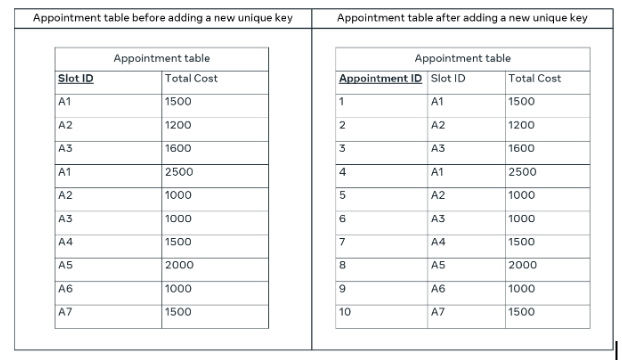
The new appointments table can be created in SQL using the following code:
CREATE TABLE Appointments
(AppointmentID INT NOT NULL,
SlotID, VARCHAR(10),
TotalCost Decimal, PRIMARY KEY (AppointmentID)
);You have removed the partial dependency, and all tables conform to the first and second normal forms.
Third normal form
For a relation in a database to be in the third normal form, it must already be in the second normal form (2NF). In addition, it must have no transitive dependency. This means that any non-key attribute in the surgery table may not be functionally dependent on another non-key attribute in the same table. In the surgery table, the postcode and the council are non-key attributes, and the postcode depends on the council. Therefore, if you change the council value, you must also change the postcode. This is called transitive dependency, which is not allowed in the third normal form.
| Surgery number | Region | Surgery council | Postcode |
|---|---|---|---|
| 3 | West London | Harrow | HA9SDE |
| 4 | East London | Hackney | E1 6AW |
| 5 | West London | Harrow | HA862E |
In other words, changing the value of the council value in the above table has a direct impact on the postcode value, because each postcode in this example belongs to a specific council. This transitive dependency is not allowed in the third normal form. To fix it you can split this table into two tables: one for the region with the city and one for the surgery.
Location table
| Surgery number | Postcode |
|---|---|
| 3 | HA9SDE |
| 4 | E1 6AW |
| 5 | HA862E |
The new surgery location table can be created in SQL using the following code:
CREATE TABLE Location
(SurgeryNumber INT NOT NULL,
Postcode VARCHAR(10), PRIMARY KEY (SurgeryNumber)
);Council table
| Surgery council | Region |
|---|---|
| Harrow | West London |
| Hackney | East London |
The new surgery council table can be created in SQL using the following code:
CREATE TABLE Council
(Council VARCHAR(20) NOT NULL,
Region VARCHAR(20), PRIMARY KEY (Council)
); This ensures the database conforms to first, second, and third normal forms. The following diagram illustrates the stages through which the data moves from the unnormalized form to the first normal form, the second normal form, and finally to the third normal form.
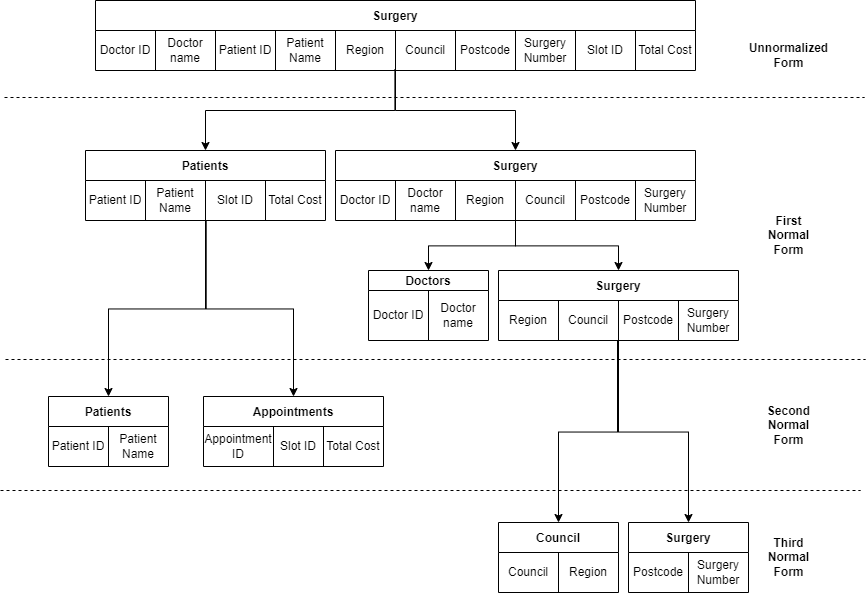
However, it’s important to link all tables together to ensure you have well-organized and related tables in the database. This can be done by defining foreign keys in the tables.
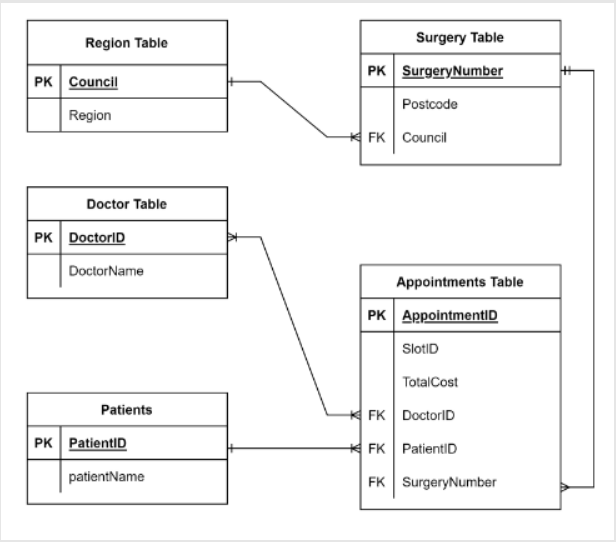
The third normal form is typically good enough to deal with the three anomaly challenges – insertion, update, and deletion anomalies – that the normalization process aims to tackle. Completing the third normal form in a database design helps to develop a database that is easy to access and query, well-structured, well-organized, consistent, and without unnecessary data duplications.
First normal form 1NF
As a database engineer, you’ll very often come across columns in a table that are filled with duplicates of data and multiple values. This can make it quite challenging to view, search and sort your data. But with the correct implementation of normalization, this challenge can be dealt with.
The normalization process makes it easier and more efficient for engineers to perform basic database tasks. It’s an especially useful process for helping to fix the well-known insert, delete, and update anomalies.
However, in order to achieve database normalization, you first need to perform the three fundamental normalization forms. The database normalization forms include:
- first normal form or 1NF
- second normal form or 2NF
- third normal form or 3NF
These rules enforce data atomicity and eliminate unnecessary repeating groups of data in database tables.
Data atomicity
Data atomicity means that there must only be one single instance value of the column attribute in any field of the table. In other words, your tables should only have one value per field.
By eliminating repeating groups of data, you can avoid repeating data unnecessarily in the database. Instances of repeated data can cause data redundancy and inconsistency.
Unnormalized table called Course Table within a college database:
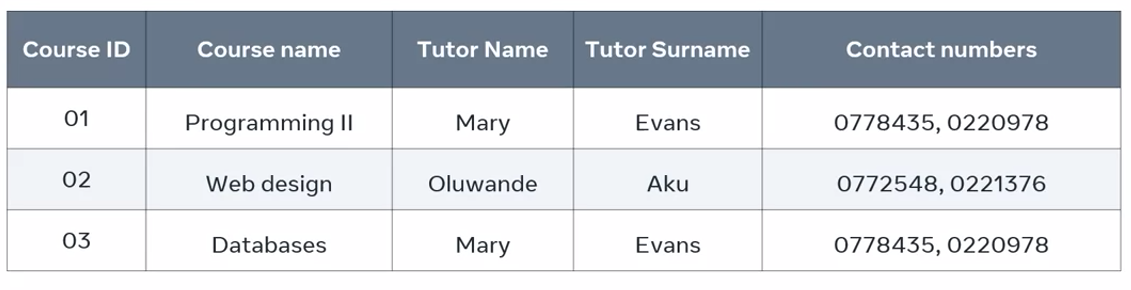
It includes information about the colleges computing courses, along with the names and contact details of the course tutors. The course ID column serves as the table’s primary key.
However, there are multiple values in each row of the contact number column. Each row contains two contact details for each tutor, a cell phone number, and a landline number.
This table isn’t in 1NF. It violates the atomicity rule by including multiple values in a single field.
I can try and fix this by creating a new row for each number. This solves my data atomicity problem. The table now has just one value in each field.
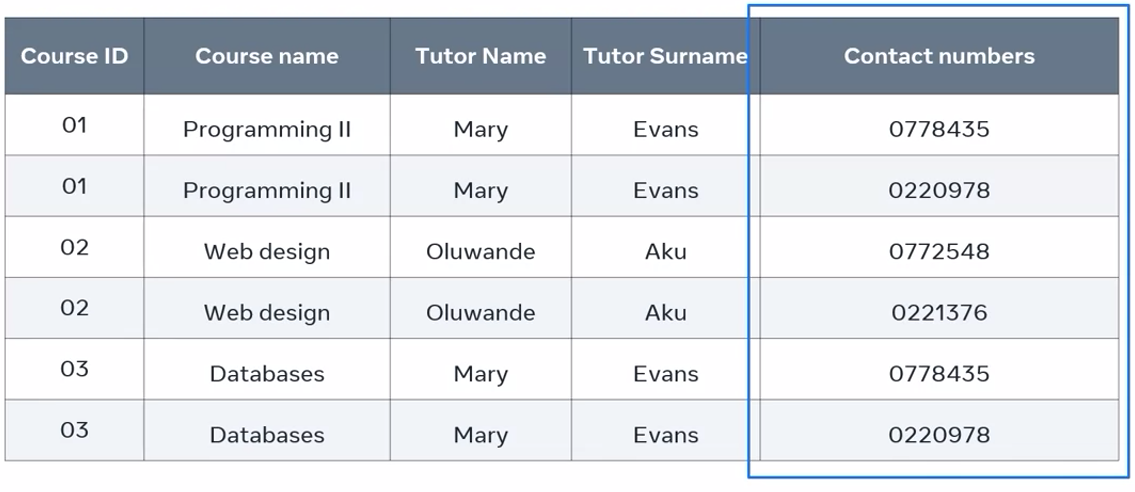
But this solution has also created another problem. The primary key is no longer unique because multiple rows now has the same course ID.
Another way that I could solve the problem of atomicity while retaining the primary key is by creating two columns for contact numbers. One column for cell phones and second column for landline numbers.
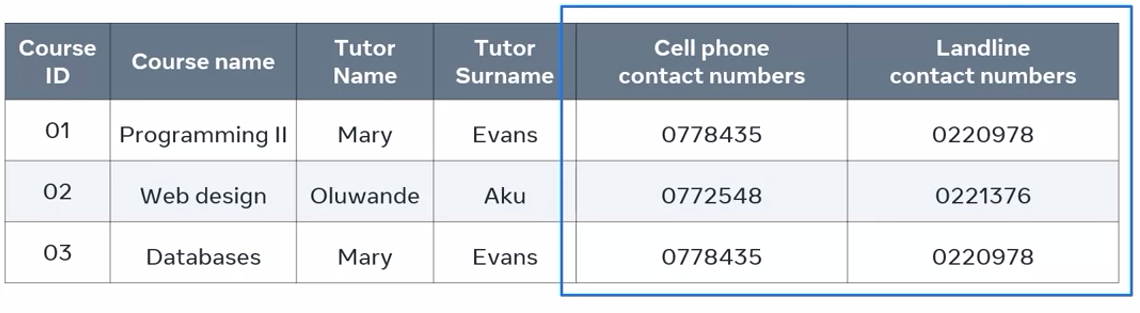
But I still have the issue of unnecessary repeated groups of data. Mary Evans is the assigned tutor for two of the courses. Her name appears twice in the table as do her contact details. These instances of data will continue to reappear if she’s assigned more courses to teach.
It’s likely that our details will appear in other tables within a database system. This means I could have even more groups of repeated data. This creates another problem. If this user changes any of their details, then I’ll have to update their details in this table and all others in which it appears. If I miss any of these tables, then I’ll have inconsistency and invalid data within my database system.
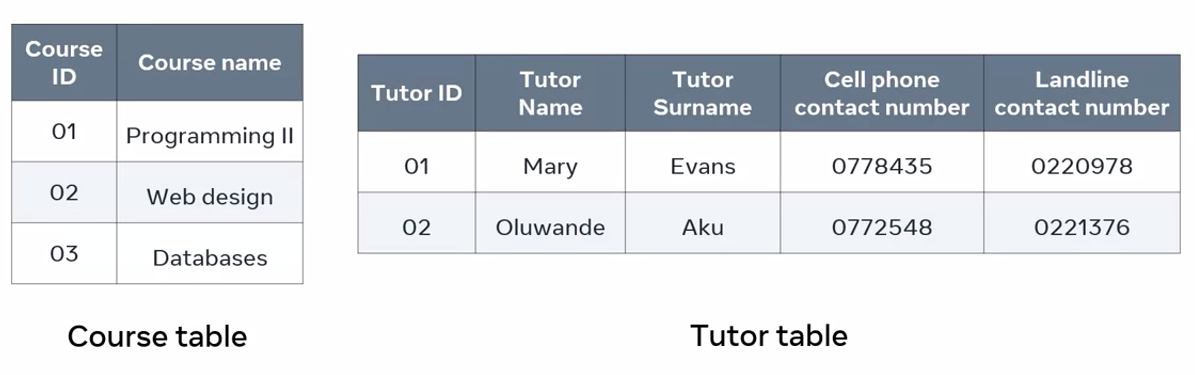
To solve this issue, I can redesign my table to adhere to 1NF or first normal form. First, I identify the repeating groups of data. In this case is the tutor’s name and contact numbers.
Next, I identify the entities I’m dealing with, which are course and tutor. Then I split the course table so that I now have one table for each entity. A course table that contains information about the courses. I choose a table that maintains the name and contact numbers of each tutor.
Now I need to assign a primary key to the tutor table. I select that tutor ID column.
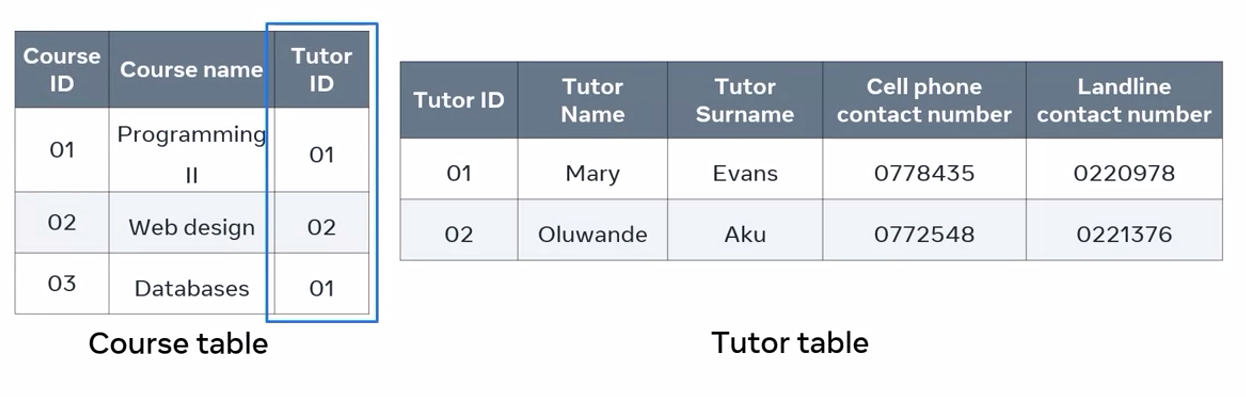
I’ve solved the problem of data atomicity, but I also need to provide a link between the two tables. I can connect the two tables by using a foreign key. I just add the tutor ID column to the course table. Now both tables are linked. I’ve now achieved data atomicity and eliminated unnecessary repeating groups of data.
Second normal form 2NF
Database normalization is a progressive process. So you must be familiar with 1NF before you can implement 2NF.
Why do database developers require database normalization? If you’re going to store content, you should aim to have the best possible database. Best means that it is a proper structure that reduces duplication and ultimately allows for accurate data analysis and data retrieval.
To get the best results, engineers build tables in a way that optimizes the database structure.
functional dependency
Functional dependency refers to the relationship between two attributes in a table. The unique value of a column in a relation determines the value of another column.
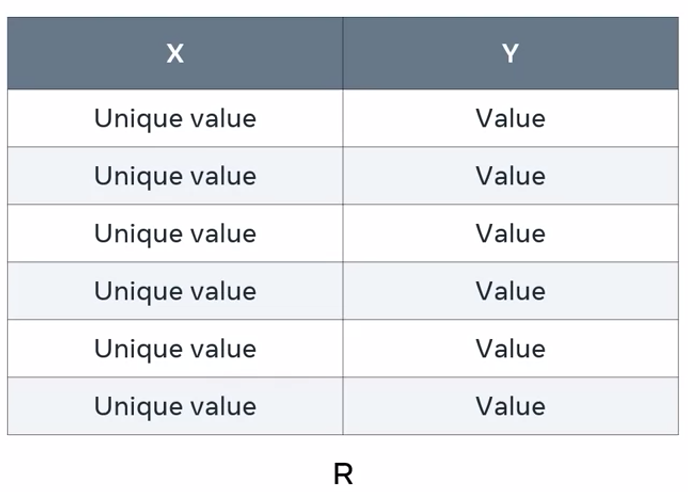
This table contains two columns called X and Y, respectively. X is a column with a set of unique values which are not replicated elsewhere in the table, a primary key, for example. Y is the column without a set of unique values like a non-primary key.
R is the table or relation in which the columns X and Y exist. Y as a non-primary key with duplicated values is dependent on X. This is because X is the table’s primary key as it only contains unique values.
a table called Student that holds key information on students in a college:
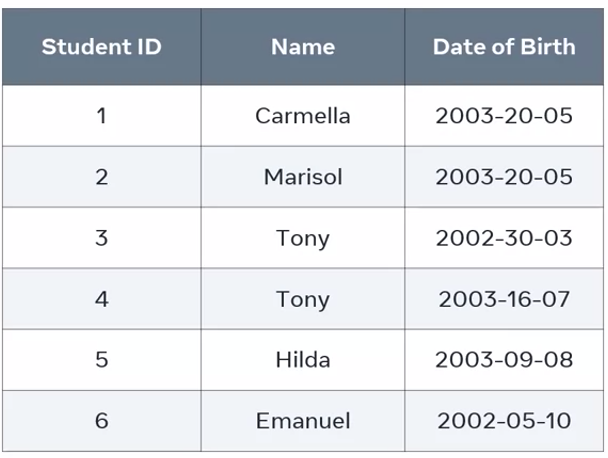
I need to use this table to find the date of birth for a specific student. I can’t use the name column because it has duplicated values. There are two students named Tony. If I query this column, I’ll just receive both instances of Tony. I can’t use the date of birth column either because there are two students who share the same date of birth.
But I can complete this task by using the student ID column. All values in this column are unique, so it is designated as the table’s primary key. The values of this primary key column determine the information of the other columns.
This means that each column in the table is functionally dependent on the student ID column. It’s the only column that can be used to return specific data.
Partial dependency
Partial dependency refers to tables with a composite primary key. This is a key that consists of a combination of two or more columns.
a table that shows the vaccination status of patients in a hospital database:
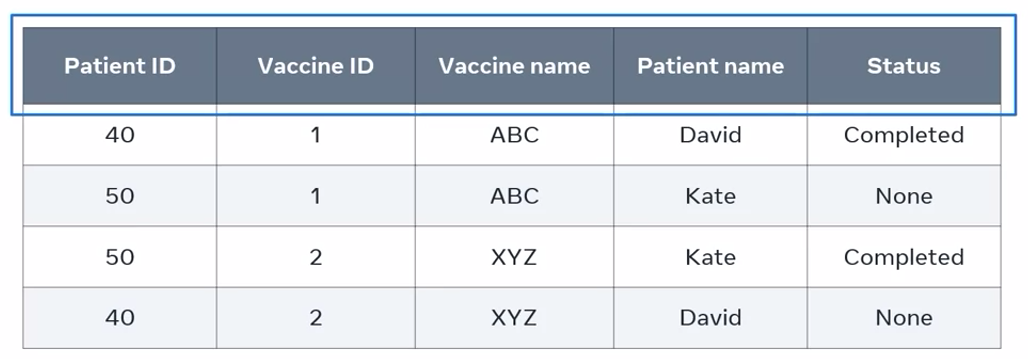
The table shows the vaccination status of two patients, David and Kate. It also displays the patient ID, vaccine ID, and vaccine name. There is no one single column with unique values in each row. There is no single column that can be used as a primary key.
It’s best to combine both the patient ID and vaccine ID columns as a composite primary key to create a unique value in each record.
The vaccination table must meet the second normal form or 2NF. All non-key attributes, the vaccine name, patient name, and status, must depend on the entire primary key value which are patient ID and vaccine ID. It can’t depend on just part of the value, otherwise this creates partial dependency.
Let’s apply this rule to find out if it’s true for every non-key column. How do I check that the patient with the ID of 50 has taken vaccine 1? I check the value of both the patient ID and the vaccine ID keys. The combined value is the only way to return the vaccination status value of a specific patient.
This means that there is a functional dependency between the status value and the primary key value.
But if I just want to find out the vaccine name, then I don’t need both combined values. The only information I need to return the vaccine name is a vaccine ID. As you learned earlier, this is called partial dependency. This should be avoided in most instances as it violates the 2NF rule. Similarly, if I want to identify the patient’s name, I don’t need both combined values. I can just use the patient ID to return the patient’s name.
Upgrading to 2NF
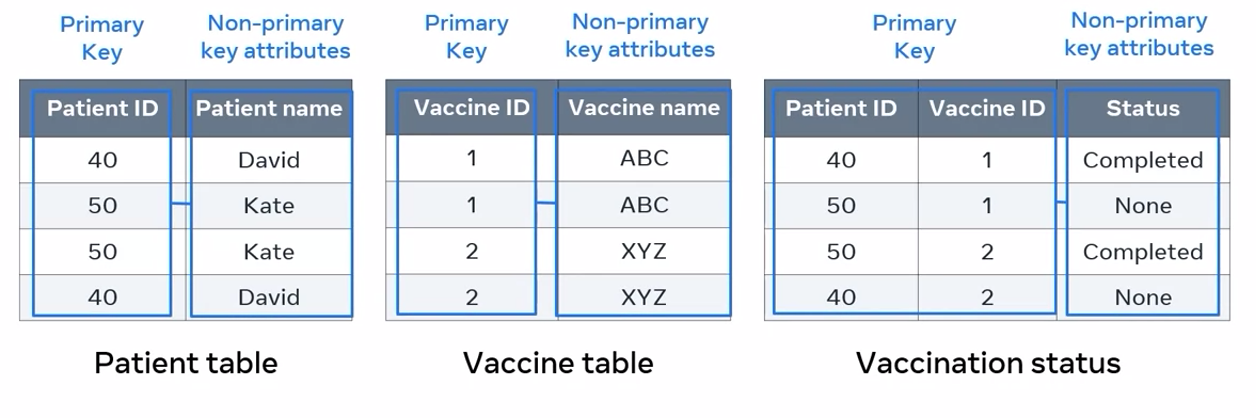
First, I need to make all non-key columns dependent on all components of the primary key. I identify the entities included in the vaccination table. In this instance there are three entities:
- Vaccination status, as represented by the status column
- vaccine, which is the vaccine ID and vaccine name columns
- patient, represented by the patient name and patient ID columns
I then break up the table into three separate tables as follows: Patient table, vaccine table, and vaccination status. Now in each of these new tables, all non-primary key attributes depend only on the primary key value. I’ve eliminated all unnecessary replication of the vaccine and patient names within the vaccination table. The three tables are now in the second normal form, or 2NF.
Third normal form 3NF
A database must be in first and second normal form before it can be in third normal form. In addition to these rules, databases can contain any instances of transitive dependency.
Transitive dependency
In the context of third normal form, transitive dependency means that a non-key attribute cannot be functionally dependent on another non-key attribute. In other words, non-key attributes cannot depend upon one another. A key attribute in a database is an attribute that helps to uniquely identify a raw of data in a table.
basic table with three columns; A, B, and C:
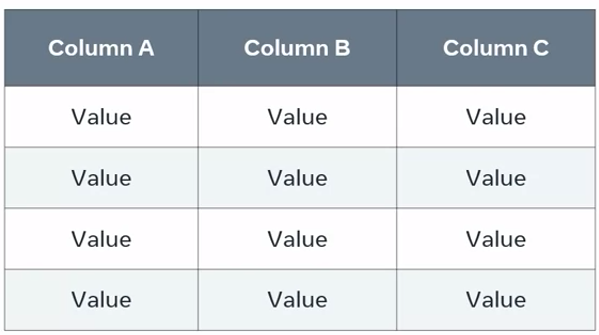
The concept of transitive dependency means that the value of A determines the value of B. Likewise, the value of B determines the value of C. The relation between these table columns is represented by A, B, and C.
This means that A determines C through B. This is the type of relation that database engineers called transitive dependency.
a table of best-selling books within Europe from the database of an online bookstore:
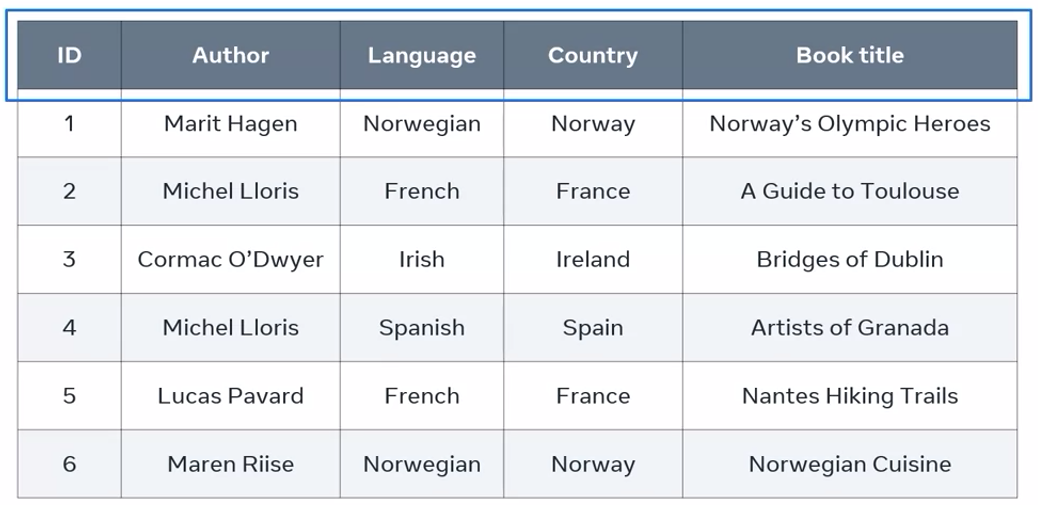
In this table, ID is the only key or primary key that exists in the table. All other attributes are non-key attributes. But to determine what these non-key attributes are, I most used the ID of the top-selling books.
This means if I want to find any specific information about any attribute, I need to use the ID attribute value to find the targeted attribute value.
However, it’s also possible to determine the country based on the language, or to determine the language based on the country, and both country and language are non-key attributes.
For example, in the context of Europe, it’s always possible to determine the country is France, if the language is French, and vice versa. This means that I have a transitive dependency in this relation.
A non-key attribute depends on another non-key attribute. This dependency relation can be presented as follows : Language determines country, and country determines language.
The rest of the attributes are fine as they only depend on the ID primary key. You can’t say, for instance, that author name determines book title, or that author name determines language.
How do I solve this transitive dependency within my table and remove any repetition of data?
I can split the table into two tables while joining them to conform with 3NF rules. I keep the top books table, while splitting off the country and language columns into a new table called country. But I also leave the country column inside the top books table as a foreign key that connects the two tables.
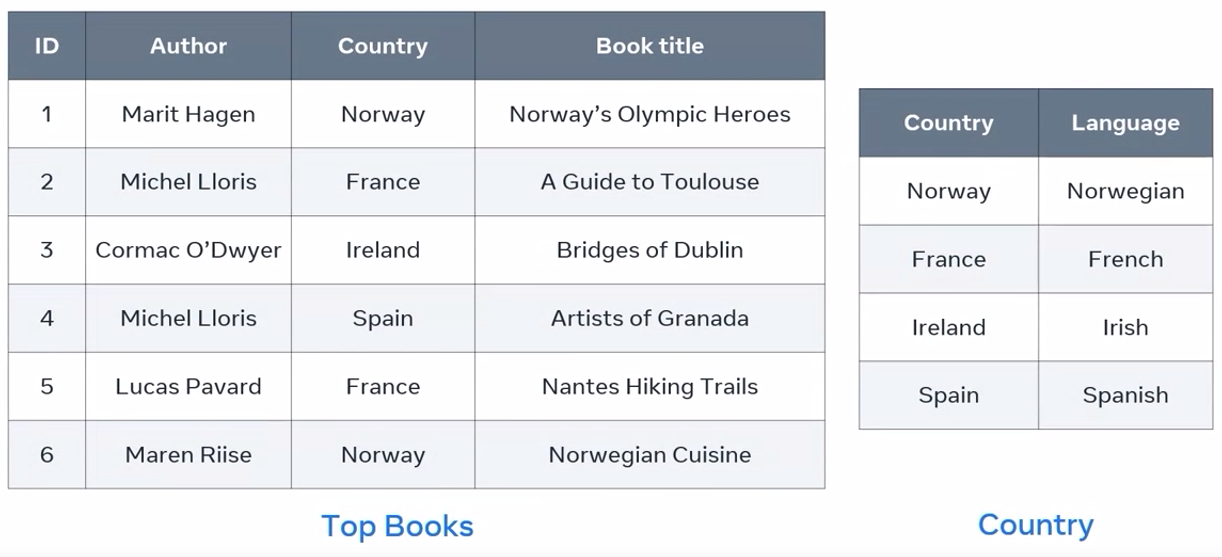
The country table now holds just four records with no repetition of data. There’s no need for language column within the top books table. Stating the country is enough to determine the language. Most importantly, all non-key attributes are determined only by the primary key in each table. This means that my table then meets the requirements of 3NF.
Additional resources
The following resources introduce key concepts of database design and anomalies. They also provide good examples of first, second and third normal forms.
Previous one → 10.Relational database design | Next one → 1.Course Introduction