Popular packages: NumPy, pandas, Matplotlib, etc
You can think of this collection of packages like a traditional real-world library. Each package is a book or magazine, and this library gets bigger every day.
Package
In programming, a package is a directory or folder, and in the same way, a module is a file or document. You import packages in the same way as a module using the import statements.
Like with the import statements, it’s important to remember that unless defined correctly, the import serves no purpose.
import foo
# Nothing happensfrom foo import awhere foo is a package and a is a module.
Exploring the packages directory structure or referring to code blocks online can save time. To work with packages in Python, it’s important to know that PIP is the default package manager, and Python Package Index, or PyPI is the package index where you can find unpublished packages.
Python usage nowadays
Python has an extensive collection of packages. As a developer starting out, it can be overwhelming, but it’s important to understand what Python is most widely used for today.
The major application areas for Python are:
- data science
- AI and machine learning
- web frameworks
- application development
- automation
- hardware interfacing
Categories of Packages
With this in mind, packages can be grouped into categories.
For example:
- built-in packages
- data science
- machine learning and AI
- web and GUI development
Built-in Packages
These are packages that don’t need to be installed separately and can be used as soon as you’ve installed Python. Almost every project uses one or more of these built-in packages, so, it’s worth getting to know them well.
- OS
- SYS
- CSV
- JSON
- importlib
- re
- math
- intertools
Data Science Packages
- NumPy
- SciPy
- NLTK
- Pandas
This’s what we use for data exploration and manipulation.
Other packages like
- Open CV
- matplotlib are used for image processing and data visualization.
AI & ML Packages
Within the world of machine learning or ML and artificial intelligence or AI, the most popular packages are:
- TensorFlow
- PyTorch
- Keras
- PyTorch
- Keras
PyTorch and Keras are currently the most popular for deep learning and neural network implementation.
There are other packages such as
- SciPy
- Scikit-learn
- Theano
Choosing which package to use will depend on the scale and scope of the project and how familiar you become with the packaging question.
Web Development Packages
NOTE
Python today is primarily used for ML, AI, and web development.
- Flask : which is a lightweight micro-framework.
- Django : which is a full-stack framework
- cherry pie
- pyramid
- beautiful soup
- selenium
Other Packages
There are also other packages for robotics, game development, and other specialized domains. For any domain you want to work in, you’ll find several Python packages relevant to it. While no one package may be a perfect fit for your projects, the open source community of Python developers is working relentlessly to fill the gaps.
As I begin a Python coder, most functions you need will be met by one package. To continue expanding your knowledge of Python packages, you should think of a project you’d like to create an experiment with the packages I’ve mentioned in this video.
Popular Packages: Examples
When I talk about popular packages in Python, it includes both built-in and third-party libraries. Once imported within the program, the usage of these packages follows the same structure and rules as regular code you would encounter without the import. You have explored some of the popular package names in the domains of data science, ML, and Web earlier on in the course. Here are a few examples of using these packages that will help you get comfortable with the idea.
Before you use any package, the first piece of code that you must always use is the import statement. That is true even in the case of built-in packages. For example, if you want to use the json package, you will first add a line such as:
import jsonNumpy
Assuming there is already an installation for the numpy package, the code for it can be as follows:
import numpy as np
a = np.zeros(10)
print(a)
b = np.full((2,10), 0.7)
print(b)
c = np.linspace(0,25,7)
print(c)
print(type(c))The output for the code above is:
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[[0.7 0.7 0.7 0.7 0.7 0.7 0.7 0.7 0.7 0.7]
[0.7 0.7 0.7 0.7 0.7 0.7 0.7 0.7 0.7 0.7]]
[ 0. 4.16666667 8.33333333 12.5 16.66666667 20.83333333 25. ]
<class 'numpy.ndarray'>- The
zeros()function inside numpy creates an array with n number of zeroes inside it. - The
full()function creates a two-dimensional matrix of dimensions 2 x 10 consisting only of the values 0.7. - In the example,
linspace()function divides the values between 0 and 25 in 7 equal parts. The resultant matrix is in the output. - Finally, when you see the data type of c, it is a special data-type created and used in numpy called as ndarray. If you try the output for
aandb, it will also be ndarray as numpy deals exclusively with ndarray, which is a substitute for lists and is far more efficient. - These are some of the functions provided by numpy.
Pandas
Now you will explore the usage of another library that closely works with numpy and other data science libraries called pandas.
import pandas as pd
a = pd.DataFrame({'Animals': ['Dog','Cat','Lion','Cow','Elephant'],
'Sounds':['Barks','Meow','Roars','Moo','Trumpet']})
print(a)
print(a.describe())
b = pd.DataFrame({
"Letters" : ['a', 'b', 'c', 'd', 'e', 'f'],
"Numbers" : [12, 7, 9, 3, 5, 1] })
print(b.sort_values(by="Numbers"))
b = b.assign(new_values = b['Numbers']*3)
print(b)Output:
Animals Sounds
0 Dog Barks
1 Cat Meow
2 Lion Roars
3 Cow Moo
4 Elephant Trumpet
Animals Sounds
count 5 5
unique 5 5
top Dog Barks
freq 1 1
Letters Numbers
5 f 1
3 d 3
4 e 5
1 b 7
2 c 9
0 a 12
Letters Numbers new_values
0 a 12 36
1 b 7 21
2 c 9 27
3 d 3 9
4 e 5 15
5 f 1 3
In the four outputs in this code, I created a pandas DataFrame in the code above called a.
- The first output is for the DataFrame called
athat displays the output in a very systematic format. - The second output uses the
describe()function in pandas that will give the count, frequency, top values and frequency among other values. - In the second DataFrame,
bconsists of letters and numbers in random order. - The third output is a sorting function that will provide a sorted table leading to shuffling of the data entries in the table.
- Lastly, the
assign()function takes the values present inside the table, performs an operation over them and creates a new variable callednew_valuesthat is then added to the table.
Pandas, just like Numpy is very widely used and has a vast variety of functionalities present in addition to the ones mentioned.
NLTK
NLTK as mentioned earlier, is a library in Python used for Natural Language Processing. Here are some of the things you can do with it.
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
text = "Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book."
# Print statement 1
print(word_tokenize(text))
# Print statement 2
print(nltk.tokenize.sent_tokenize(text))
stopwords = stopwords.words("english")
new_text = []
for i in text.split():
if i not in stopwords:
new_text.append(i)
# Print statement 3
print(new_text)Output:
['Lorem', 'Ipsum', 'is', 'simply', 'dummy', 'text', 'of', 'the', 'printing', 'and', 'typesetting', 'industry', '.', 'Lorem', 'Ipsum', 'has', 'been', 'the', 'industry', "'s", 'standard', 'dummy', 'text', 'ever', 'since', 'the', '1500s', ',', 'when', 'an', 'unknown', 'printer', 'took', 'a', 'galley', 'of', 'type', 'and', 'scrambled', 'it', 'to', 'make', 'a', 'type', 'specimen', 'book', '.']
['Lorem Ipsum is simply dummy text of the printing and typesetting industry.', "Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book."]
['Lorem', 'Ipsum', 'simply', 'dummy', 'text', 'printing', 'typesetting', 'industry.', 'Lorem', 'Ipsum', "industry's", 'standard', 'dummy', 'text', 'ever', 'since', '1500s,', 'unknown', 'printer', 'took', 'galley', 'type', 'scrambled', 'make', 'type', 'specimen', 'book.']NLTK is a huge library and it is inadvisable to import all its packages and subpackages. If you examine the code, you will realize that only the required functionalities from the subpackages such as corpus and tokenize are imported within the code.
- First a block of text is copied inside the code-block and assigned to a variable called
text. - The first function used is
word_tokenize(). This takes this text and produces the first part of the output in which the words are ‘tokenized’ or simply separated by a whitespace. The same can be done with thesplit()function in the string, but the use of the package is far more efficient when it comes to larger blocks of code. - The second function
sent_tokenize()takes this block of text and tokenizes by ‘sentences’. - For the third output, I first split the code and remove what is called ‘stopwords’. Stopwords are words in the English language that can be considered redundant and adding little value while you are undertaking natural language processing. These include words such as ‘a’, ‘the’, ‘him’. First I’ll create a list of these stopwords and then remove them using a
for loopto form a new list callednew_text. You will notice the difference by comparing the first and the final output of the code.
We have covered only a couple of examples here from couple of libraries and there is a plethora of options available with different packages in Python. The best way to learn them is through practice and exploration.
Data analysis packages
The last decade has seen exponential growth in all data science areas. The demand for data analysis and scientists is continually increasing, as it’s a requirement that developers to incorporate scientific and data analysis into their code.
Python has emerged as one of the most popular languages with data scientists. One of the main reasons for its popularity is the large number of different open source packages. These have been developed by thousands of contributors collaborating to provide free, usable resources.
Many packages are top-rated because they are efficient and provide outstanding functionality.
- Numpy
- Scipy
- Matplotlib
- Scikit-Learn
Scikit-Learn
Scikit-learn is used for predictive learning, and is built on top of other popular packages. It consists of various supervised and unsupervised machine learning algorithms for classification, regression, and SVMs.
Modelling data is the primary focus of this library, and it provides popular models such as clustering, feature extraction and selection, validation and dimensionality reduction.
Pandas
Python Data Analysis
This is a data analysis and manipulation tool. It’s used primarily for working with datasets and provides functions for cleaning, analyzing, and manipulating data.
Using it, I can compare different columns and find the arithmetic mean, max and min values.
The primary data structures used in pandas are series and Dataframes. While series are single-dimensional and can be compared to a column in a table, dataframes are multi-dimensional and can potentially store tables efficiently.
They are agnostic to the datatypes being stored. Pandas most common applications are reading CSV files and JSON objects and using them within Python code for faster retrieval.
Pandas are known to bring speed and flexibility to data analysis. Pandas library is normally imported by the code import pandas as pd.
NumPy
Numerical Python
It’s a powerful library forming the base for libraries such as Scikit-learn, Scipy, Plotly, and Matplotlib.
Python scientists use the abilities of NumPy, especially when working in scientific domains such as
- signal
- image processing
- statistical computing
- quantum computing
NumPy carries out the calculations needed for algebraic areas such as Fourier transforms and matrices. The backbone data structure in NumPy is called ND array or N-dimensional array, which substitutes the conventional use of lists in Python, and is a much faster solution than lists.
The dimensions in NumPy are called axes and the number of such axes is called a rank.
Conventionally, NumPy is imported with import NumPy as np.
Matplotlib
Matplotlib is the visualization library used in Python. It can be used to create static, interactive and animated visualizations.
Many third-party tools such as ggplot and seaborn extends the functions of matplotlib.
These functions are located inside the pyplot stub package. Matplotlib is imported with import matplotlib.pyplot as plt.
to0
An example such as libraries to0 uses the matplotlib and NumPy libraries to for instance, display a graphical representation of students in a class or the distribution of their scores.
Machine learning, deep learning and AI: PyTorch, TensorFlow
Artificial Intelligence or AI, is broadly about making machines think like humans. Data science primarily focuses on the management and exploration of data which may include media such as text, audio, images and video.
Machine learning or Ml is a subsection of AI and deals with algorithms for training and generating insights from data. Many fields utilize machine learning.
- natural language processing
- deep learning
- sentiment analysis
- recommended engines
- computer vision
- speech recognition
With the amount of text, image and video data available today, data science and AI in particular are in greater demand than ever. Python is one of the most popular languages used in these domains. The reasons are, seeing tactical efficiency and readability, flexibility with different languages, frameworks and operating systems welcoming and large community of developers.
Ability to build ML models without having to understand the intricacies. Use a friendly debug and testing tools and modular structure. These will promote the development of many primarily open source libraries and frameworks.
Package / Library / Framework
A package is a collection of modules and both library and framework are often used interchangeably with packages.
Libraries can also be a collection of packages with specific purpose, whereas the term framework is usually used where certain flow and architecture is involved.
Some of the most popular ML libraries in use today are in the areas of:
- deep learning and neural networks
- Computer vision and image recognition
- Natural language processing
- data visualization
- web scraping
It’s important to understand that these are broad categorizations. Most of the libraries associated with them are not restricted to a particular field. Every project is unique and should be treated as such. The right selection of the library can save precious time when coding.
Big Data and Analysis with Python
With the advent of social media and its widespread acceptance came the unprecedented need for data management. Now billions of gigabytes of data are produced every day and much of it is generated by the end-users. Organizations recognized the huge potential in harnessing this data using predictive and machine learning algorithms to generate insights. But before tackling that challenge, came the challenge of efficiently and systematically storing and handling this data in a way that made it available for quick access.
Big data is the management of large sets of data, both structured and unstructured. Today, this large amount of data is stored in the form of data warehouses and data lakes, both on servers and in the cloud. The main characteristics that are commonly identified for use of Big Data tools are Volume, Variability and Velocity.
Volume is the size of data under question and, if large enough, may require different handling to traditional data storage and management.
Variability or veracity refers to the inconsistency that may be present in this data. In huge data repositories, it is difficult to intervene manually on every wrong entry and thus enough scope for variability must be defined and established while handling such data.
Velocity is the speed of handling this data. With data sources such as social media which are continually active, there is a need for constant updates as well as robust storage. When there is a need to be processed, it should also not create a bottleneck where data retrieval takes longer. As such, velocity plays a very important role in Big Data.
This is the ability to handle a large amount of heterogeneous data with ease of access and speedy processing. The next step in this process is when this data is analyzed and is broadly called data analysis. The final step is publishing this data in form of reports, visualizations and web pages, as per the requirement.
The whole pipeline can be summarized as below:
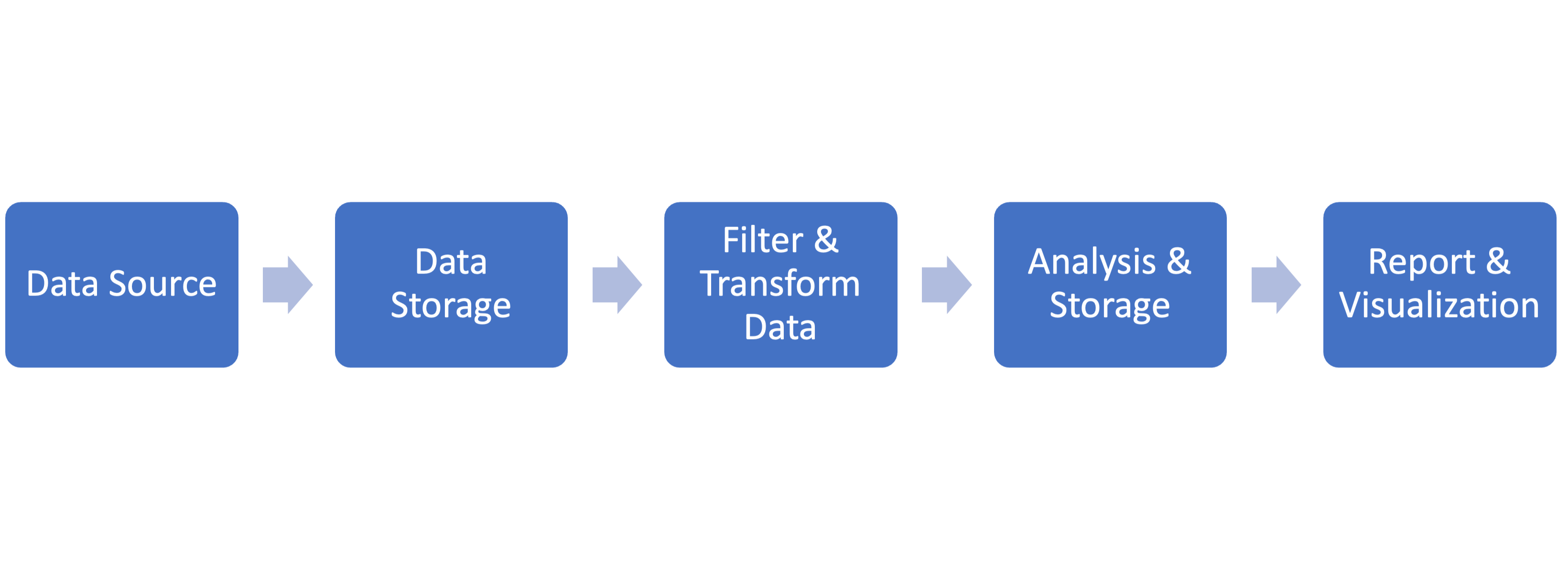
Here are several reasons why Python has found a place in the domain of Big Data:
Ease of use: Ease of use is a prerequisite for any large-scale and commonly used technology and language. Python helps setting up and running infrastructure with just a few lines of code.
Licensing structure and open-source nature: The open source paradigm has picked up immensely in recent years. Python provides many very well developed open-source libraries and frameworks, even for large scale applications. Some organizations prefer this, as it saves on cost, as well as providing easier licensing.
Active community: The Python community today is vast and very supportive. This helps with the swift resolution of issues a user may face, as well as the development of new features when required.
Libraries: Possibly the strongest reason for the acceptance of Python is the host of libraries that provide direct support for Big Data. In addition, there are many packages that also aid in bridging the gap between Python and other languages and tools enabling swift deployment of services.
High compatibility with Hadoop and Spark: Hadoop and its Hadoop distributed file system is arguably one of the best solutions for large-scale storage. The support available in Python has also helped in wider acceptance of Python. The same can be said about Spark as Python has supportive libraries such as PySpark and host of API libraries that facilitate its usage.
High processing speed: Python has support for prototyping and with its Object-oriented methodology, processing in Python is much better in comparison to other languages. With its increase in speed, Python is also able to provide adequate stability in its usage.
Portability and scalability: Broadly as mentioned before, Python’s support for cross-language platforms and operations, its ease of extensibility, various libraries, support for frameworks and API overall, makes it easy to scale and flexible.
Python tools and libraries: Most of the libraries in Python that are used for Big Data are widely common and is associate with Data Sciences and Machine Learning. Big Data includes wide-scale usage and acceptance of libraries such as: Numpy, Pandas, Scikit-learn and Scipy. To name just a few.
Additionally, here are a few more libraries that are more specific to a Big Data domain such as:
RedShift and S3: Amazon services are used with their cloud services. S3 is a storage service and RedShift is a data warehousing service.
BigQuery: Developed by Google, BigQuery is a Cloud service library that is useful with RESTful APIs.
PySpark: This is an open-source framework used for large scale data processing and works with resilient distributed datasets.
Kafka: This is a publish-subscribe messaging system that receives logs in the form of packages and is stored in partitioned spaces.
Pydoop: Pydoop provides an interface between Hadoop and Python and support for handling its Hadoop distributed file systems.
Python web frameworks
Web frameworks are software applications designed to provide us with a standard way to build, deploy, and support web applications that we can use on the web. They help developers to focus on application logic and routines by automating redundant tasks, which helps cut development time. They also provide easy structuring and default model so they are reliable, stable, and easily maintainable, saving time and effort.
Web frameworks are primarily written in high-level code, which removes the overhead required for understanding concepts such as sockets, threading, and protocols. As a result, time is better spent working on application logic instead of routines.
Python is a popular framework in web development, thanks to several features such as:
- good documentation
- abundant libraries and packages
- ease of implementation
- code reusability
- a secure framework
- easy integrations
The different frameworks in Python are efficient and make it easy to handle tasks such as:
- form processing
- routing requests
- connection with databases
- user authentication
They also provide debugging and testing tools to handle profiling, test coverage, and test automation, etc.
Types of Web Frameworks in Python
- Full-stack
- microframeworks
- asynchronous
Full-stack
Fullstack frameworks are considered a one-stop solution and usually include all the required functionalities. This can include:
- form generations and validators
- template layouts
- HTTP request handling
- WSGI interfaces for connection with web servers
- database connection handling
Some of the most popular Python frameworks are:
- Django
- Web2py
- Pyramid
Microframeworks
Microframeworks are a lighter version of fullstacks that do not offer as many patterns and functionalities. They are usually used in smaller web projects and building APIs.
- Flask
- Bottle
- Dash
- CherryPy
Asynchronous
As the name suggests, asynchronous framework types are used to handle a large sets of concurrent connections.
They are mainly built using Async IO networking libraries.
- Growler
- AIOHTTP
- Sanic
Choosing the right framework
Choosing a framework can depend on many factors. This can include things like available documentation, scalability, flexibility, and integration.
While this categorization is pretty broad, it’s important to remember that each framework in Python has its own unique set of features and functionalities. This can make certain frameworks more suitable than others for a specific project.
Two of the most widely used are flask and Django.
Django
Django is a high level framework that encourages clean design and rapid development. It’s a full-stack framework that’s rich in features and libraries. It’s secure and has templating systems and third party supports.
It primarily getting popularity due to its rapid deployment speed. You can quickly build scalable apps without extensive knowledge of low-level programming.
Flask
Flask is a microframework and better used for smaller projects. It’s easy to learn, simple to use, and as a large library of add-ons.
Additional Resources
The following resources will be helpful as additional references in dealing with different concepts related to the topics you have covered in this module:
- Popular Python packages for web development
- ML and AI libraries in Python
- Data Science libraries in Python
libraryPackageframeworkDataScienceAIMLwebPython
Previous one → 8.Modules | Next one → 10.Testing Tools