What is scaling?
If your application is not ready to handle such loads, or sudden traffic spikes, the web server, or the database server will fail to handle requests. They will either be extremely slow to respond, or go down.
That is why your production server must be scalable to sustain such loads or be responsive as your users grow.
Scalability
Scalability is the process of resizing your production infrastructure to withstand the load as it goes up, or down.
Sometimes the load could be sudden, otherwise it will continue to grow as your application gets bigger and starts to have more users. Usually in a production environment the main bottlenecks are the web server and the database server which needs to be scalable.
There are two types of scaling, vertical and horizontal.
Vertical Scaling
Under load, the web server and database is mostly fail for two reasons, lack of resources like CPU and RAM, or incorrect configuration which prevents them from using available resources.
If you are failing due to the lack of resources, it’s a comparatively easy fix. The solution is to add more storage, RAM, or processing cores to the Virtual Machine, or upgrade the physical processor.
This process of adding RAM, or CPU, or storage is called vertical scaling.
But there is a problem with vertical scaling, you cannot add an infinite amount of processor cores, RAM, or storage in a physical machine. How many resources you can add depends on the hardware configurations. Once the limit is reached, you cannot scale anymore. Moreover, adding physical hardware like this can be very expensive and unrealistic over time.
Vertical scaling is quicker than horizontal scaling and has easier configuration. Therefore, it looks appealing as an easy fix, but beware of its limitations.
It can be costly over time, or when it needs repairs. Always keep in mind that you cannot scale infinitely with vertical scaling.
Horizontal scaling
However, there is another type of scaling that overcomes these issues and that is horizontal scaling. In fact, it’s considered more efficient and cost-effective.
In this process you add nodes, or virtual servers as the load goes up and remove the nodes when they go down. For example if one web server can handle 2,000 requests per minute, to withstand the load of 10,000 requests per minute, you need to add four extra nodes to the web server.
Five nodes will be capable of handling 10,000 requests per minute without any issues.
The same thing goes for the database, you can use database replication, or database clustering to create multiple database nodes as the load grows and when the load returns to normal, you can remove those nodes again.
An application with a proper horizontal scaling setup can be scaled to handle a tremendous amount of load. It’s infinitely scalable with horizontal scaling.
However, it’s not a plug and play process. Configuring your application infrastructure to be horizontally scalable takes time and effort.
Auto-scaling
Some Cloud providers offer an excellent auto-scaling solution with no manual intervention, or extra configuration.
When you turn on Auto Scaling, the Cloud provider automatically adds, or removes computing nodes, memory, or other resources to keep the applications sustainable and healthy under load.
Load balancing
Load balancers help scale your application by evenly distributing loads on multiple nodes in a round-robin fashion, or based on node health.
Load balancing the web server
Your web server plays a vital role in accepting all HTTP requests, sending them to the backend scripts, getting the response, and delivering it to the client.
The web server also receives requests to serve static HTML, CSS, and JavaScript files.
Many Cloud providers offer load-balancing services. Using these, you can create multiple web servers with the same application code and link them to the load balancer.
The load balancer then accepts all HTTP requests and sends them to the web servers.
This load distribution can happen in two styles, round-robin and health based.
Round-robin
In the round-robin style, the load balancer distributes the load equally on all web servers.
But there is a problem. Not every request is the same. Some requests take a fraction of a second to finish and some take longer. In a round-robin load distribution model, if a web server is already working on a request, it may receive subsequent requests, and then take a long time to process those requests.
Health based
There’s a better way to deal with this problem. Some load balancers are configured in a way that can monitor the load on these web servers and then distribute the load only on those nodes which are available and not already loaded.
This is called health-based load balancing and works better than round-robin style.
You can use a reverse proxy to perform load balancing.
The web server serves everything including application URLs, API calls, and static files. A reverse proxy can be configured in such a way as to serve the static files by itself, and forward the applications specific URLs and API calls to the web server.
Static files includes HTML, CSS, JS, text files, and images.
This technique is widely used and improves the performance of your web server by reducing the number of requests the web server has to handle.
Offload static files
Similar to serving the static assets using a reverse proxy, you can completely offload them to an external content delivery network or CDN.
This can speed up your applications page rendering time, because CDN services create multiple copies of these static files and serve them from the client’s nearest data center.
Database load balancing
Scaling a database is more complex than scaling a web server. Sometimes vertical scaling helps, but horizontal scaling has better sustainability.
There are two popular techniques for scaling databases horizontally.
Sharding
The first one is sharding. This is when a large database is split into multiple chunks and one database server holds one chunk. One extra database is needed to keep track of these chunks for better lookup.
Master-slave replication
With the master-slave replication approach, the whole database is replicated on multiple servers. One works as a master server where the data modifications happen.
As soon as something changes, the master server writes those changes on other servers, which are called the slave servers.
All the read requests are evenly distributed to these slave servers. This way, multiple slave servers can handle more SQL queries and still remain healthy.
Most Cloud providers offer managed database servers where they internally balanced the loads and process a massive amount of data without creating trouble or going down.
Using this managed database service, the developer remains worry-free and focuses on development and business growth instead of tedious infrastructure management and DevOps processes.
The load balancing techniques discussed are considered public load balancing, because they are directly dealing with the external client requests.
Private load balancing is sometimes necessary where heavily loaded internal non-public applications, or microservices are communicating with each other over private IP addresses.
How a CDN improves scaling
Introduction
Content Delivery Networks or CDNs are widely used to store static content files like HTML, CSS, JS, and images of web applications. CDNs deliver content from servers worldwide but always from the nearest server to the client, which has many advantages.
In this reading, you will learn how these CDNs work and what their benefits are.
What is CDN
A CDN has multiple servers which are called PoP or point of service and they run in different countries across the world. When you connect your web application to a CDN, each PoP can store a copy of the static files of your web application. For instance, when a visitor browses your application from Asia, the PoP closest to that visitor’s ISP or internet service provider serves the application’s content. Below is a diagram of a typical web application architecture without a CDN.
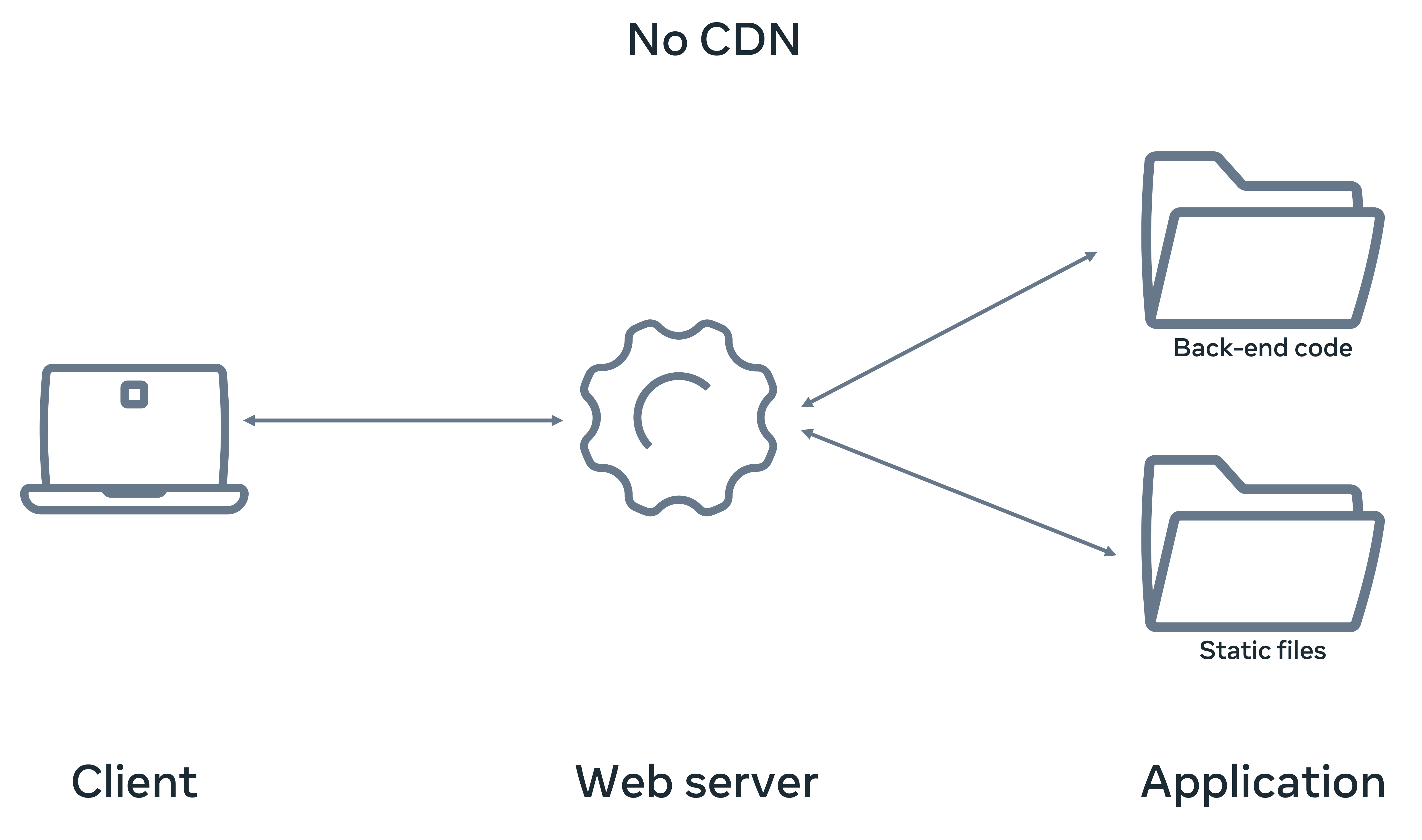
There are two significant benefits to this process of serving content via CDNs. First, your web application visitors receive the content faster than those web applications that do not use CDNs. And second, your web application is not receiving direct traffic requesting those static files. Thus, the load on the web server is reduced to a great extent.
Push versus pull CDNs
There are two types of CDN, push and pull CDNs. When your web application is connected to a push CDN you need to upload or push static files to the CDN every time you make changes to them. This can be done manually or automatically. But it requires extra effort from the application developer, and is therefore less popular.
On the other hand, a pull CDN updates files automatically. When visitors request a file, pull CDNs will check the origin server automatically to detect if the original static files have changed. An origin server is a server you use to host your web application, and this is where the static files are stored. If any changes are detected, the CDN server pulls those changed files and serves them. The new version of the files then also replaces the previous versions on the CDN. Since this is entirely automated, pull CDNs areused most often. Below is a diagram of how a pull CDN works.
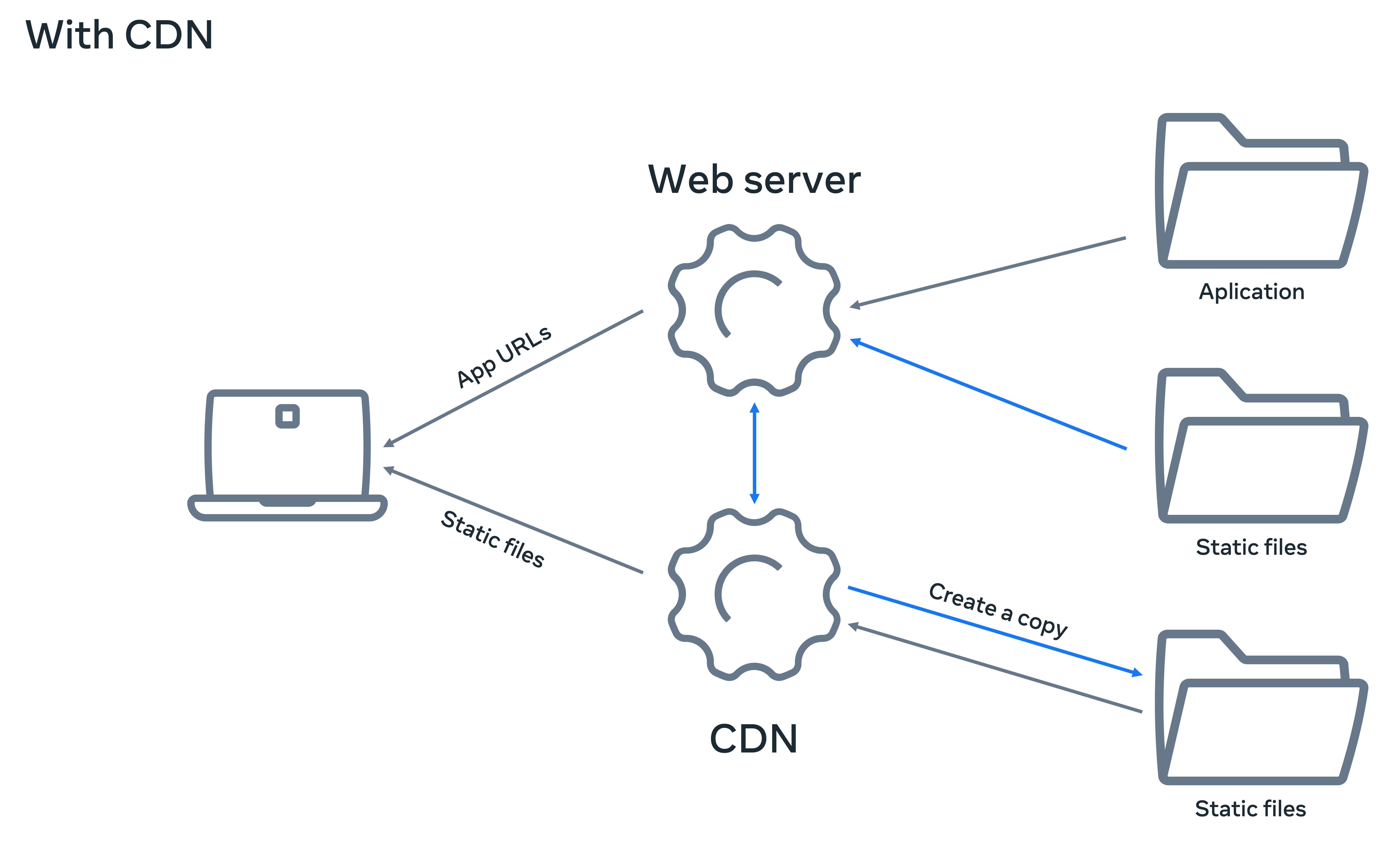
Advantages
The most significant benefit of using a CDN is the reduced delivery time for static files. When a web page renders, the static files take the longest to render. So, the faster they are served, the quicker the page will display.
Another benefit is the reduced workload on the web server. A web page can have hundreds of static CSS, JS, and image files linked to the page. For example, if there are 10 JavaScript files, 2 CSS files, and 60 image files, a single page visit will make 1+10+2+60=63 requests to the web server. If your webserver can serve 2000 requests per minute, with this calculation, it will be capable of serving only 2000/63 = 31 visitors per minute. Now, if you offload all the static files to a CDN, that means for every page visit, your webserver is getting only one request because other files are served directly from the CDN servers. The result is that your server can instantly serve 2000 visitors per minute! That’s a massive improvement for little extra cost. With less load, the web server also works more efficiently.
Another benefit is that CDNs reduce the bandwidth from the webserver. CDNs come with huge uplink capacity and can serve a tremendous amount of data every second, which may not be possible to serve from a single web server with your current provider.
And lastly, it is beneficial to use images on the CDN. Many CDN automatically reduces image size or even convert them as they are requested to more modern formats like webp. Webp is a lossless format that preserves the quality of the image.
Disadvantages
Sometimes, viewing the changed files delivered from the CDN may take time. This is because some CDNs take time to update the stored files with the newer versions. So, changes to any static file may not be instantly visible to your visitors. It may take 10 to 30 minutes or more due to different cache settings. But this rate varies significantly from provider to provider.
Another disadvantage is the bandwidth cost. When you deliver data from CDNs, the bandwidth cost will be higher than serving the files from your web server. And as your applications begin to grow, it can be costly.
Still, compared to the advantages CDNs offer, the disadvantages are far fewer and you should try to use a CDN whenever possible.
Conclusion
In this reading, you learned more about content delivery networks or CDNs, the different types and how they enable web applications to scale up. You also learned about the pros and cons of using CDNs.
ScalingDeploymentDatabaseCloud
Previous one → 9.Introduction to cloud computing | Next one → 1.Project info